バグの数は予測できるのか? 発想は斬新だけど評判の悪い「池の中の魚」モデル:山浦恒央の“くみこみ”な話(48)
プログラマーの永遠の課題「プログラム中の残存バグ数の推定」に迫るシリーズ。今回は、エンジニアの基本姿勢から逸脱した、一種のトンデモ推定法である「キャプチャー・リキャプチャー・モデル(別名、ソフトウェア版『池の中の魚』モデル」を取り上げます。
コーディングが終わり、コンパイルエラーも消え、いざデバッグ工程に突入――。このとき、「プログラムの中に隠れているバグの総数を正確に推定できたらなぁ……」と考えたことはありませんか? こう考えるのは何もプログラマーだけではありません。プロジェクトマネジャーも、プロジェト管理や品質制御の観点から、バグ総数を高精度で予測することを夢見ています。
というわけで、新シリーズでは、この「ソフトウェア中の残存バグ数の推定」をテーマに取り上げ、今回から数回にかけて解説していきます。
第1回となる今回は、「キャプチャー・リキャプチャー・モデル」、別名、ソフトウェア版「『池の中の魚』モデル(Fish-in-the-Pond Model)」を取り上げます。この技法は、エンジニアの基本姿勢から逸脱した一種の“トンデモ推定法”ですが、発想は非常にユニークで、なるほどと思わせる一面もあります。
1.残存バグ総数の推定による御利益
まず、本題に入る前に、プログラムの中に何件のバグが潜んでいるか(残存バグ数)を高精度で推定できると、どんな「御利益」があるのか整理しておきましょう。
(1)品質を定量的に計測できる
残存バグ数は、現在の「プログラム品質」を具体的な数字で表すのに、最も分かりやすく、的確な数値といえます。
(2)品質の改善度合いや推移が定量的に計測できる
バグを摘出して修正するごとに、品質は上がります。エンジニアたるもの、どれだけ品質が上がったかと聞かれ、「まあまあ動くかな?」「かなり動くようになった」「ほぼ完璧ですよ」「バッチリ動きます」のように、米国のプロジェクトでよくある“どんぶりメトリクス”で回答してはなりません。きちんとした数値で表現すべきです。残存バグ数を高い精度で予測できると、品質の改善度合いを具体的な数値で表示できます。
(3)デバッグ工程で、プログラマーにバグ摘出の具体的な数値目標を与えられる
きちんとした開発プロジェクトでは、コーディング工程が完了し、デバッグ工程に入る際、ただ漠然とバグを見つけ出すのではなく、プロジェクトマネジャーが各プログラマーに対し、「何件のバグを見つけなさい」と具体的な数値目標を提示します。そして、実際に摘出したバグ件数と目標数との比率で、デバッグ工程の進捗を表現します。例えば、あるプログラマーが開発したソフトウェアの残存バグ総数を60件と推測した場合、そのうち15件摘出していれば、デバッグ工程の進捗率は25%となります。こうすることで、目標スケジュールに対し、「3日遅れ」のような具体的な進捗制御が可能になります。この目的で使用する場合、プログラマーの尻をたたく意味で、「実際よりも少し多めに推定できる方式」が望ましいといえます。
(4)マーケットへの出荷時期を予測できる
プロジェクトマネジャーの最重要作業の1つが、現在開発中のプログラムがいつ市場に出荷できるかを正確に予想することです。「出荷基準」にはいろいろなものがありますが、「残存バグ数がゼロになった」というのも非常に重要な基準です。
以上のように、残存バグ数を高精度で予測できると、メリットが多いため、ソフトウェア工学の研究者は、いろいろな方法で残存バグ数を予測しようとしています。
2.「池の中の魚」モデル
残存バグ数の予測方法のベースとなる技法で、最も有名かつ最も評判の悪いものが、池の中の魚モデルです。
この技法は、動物学で用いる「母体数推定モデル」を応用したものです。池の中に魚が何匹いるかの母体数を推定する方法として、動物学者は「魚を捕獲し、目印を付けてリリースし、再捕獲する」方式を採ります。その具体的なステップを以下に示します(図1)。
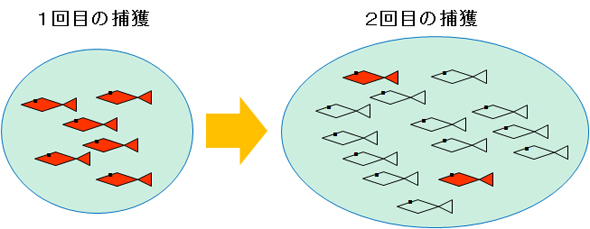 図1 池の中の魚モデル
図1 池の中の魚モデル- 魚を大量に捕まえて、目印を付ける
例えば、池に投網を打って、魚を大量に捕獲し、その魚の尻尾に赤いペンキで色を付けます - 捕獲した魚をリリースする
捕獲して尻尾を赤く塗った魚を池に返します - 数週間たって、再び魚を大量に捕獲する
尻尾の赤い魚が池にいる他の魚と十分に混じったころを見計らって、再び、池に投網を打って、魚を大量に捕獲します - 2回目に捕獲した魚の中に、尻尾の赤い魚が何匹含まれているかで母体数を推定する
2回目に捕獲した魚の中に、尻尾の赤い魚が何匹いるかをカウントし、母体数を推定します。例えば、1回目に80匹捕まえ、尻尾を赤く塗ってリリースし、2回目の捕獲で120匹捕獲したと仮定します。120匹の中に、尻尾の赤い魚が12匹いると(12/120=10%)、「最初に捕獲した『80匹の尻尾の赤い魚』は、全体の10%」であると推測し、魚全体の母数は800匹と予測するのです
3.ソフトウェア版「池の中の魚」モデル
ソフトウェア版の池の中の魚モデルが、キャプチャー・リキャプチャー・モデルです。「尻尾の赤い魚」をバグに見立て、ソースコードの中に何個のバグが存在するかを予測する方法です。以下のステップで、残存バグ数の推定を行います。
- デバッグ工程に入る前に、各プログラマーのソースコードを集める
プロジェクトマネジャーは、プログラマー全員の全ソースコードを集めます。これが最初のステップで、「池の中の魚」モデルでいうところの「1回目の魚の捕獲」に相当します - ソースコードに人工バグを埋め込む
プロジェクトマネジャーは、各プログラマーに分からないよう、集めたソースコードに、無理やりバグを埋め込みます。この「人工バグ」が先の「尻尾の赤い魚」に相当します - バグ入りソースコードをデバッグする
プロジェクトマネジャーは、人工バグ入りのソースコードを各プログラマーに返し、「では、デバッグを開始してください」と指示します。バグを検出したら、プログラマーはバグレポートを書き、バグを修正します。このバグの中には、もともとプログラムに存在していたバグと、人工バグが混在しています - 人工バグの比率から、残存バグ総数を予測する
プロジェクトマネジャーはバグレポートを分析し、もともとプログラムに存在していたバグと、人工バグ(尻尾の赤い魚)に分類します。これにより、残存バグの総数を予測します。例えば、プロジェクトマネジャーが人工バグを12件埋め込み、プログラマーがデバッグで24件のバグを摘出し、うち8件が人工バグだった場合、人工バグは全体の33%となり、元のプログラムには36件のバグがあったことになります
4.ソフトウェア版「池の中の魚」モデルの評判が悪い理由
ソフトウェア版の池の中の魚モデルは、考え方としては非常に面白く、「へぇ〜、なるほど。そんな方法があったのか!」と感心する人も少なくないと思います。しかし、発想が斬新だからといって、絶対的な効果があるとは限りません。実際、ソフトウェア版の池の中の魚モデルは、非常に評判が悪く、露骨に嫌悪感を表すソフトウェア開発者も少なくありません。なぜ、そんなにたたかれるのでしょうか。その理由を以下に示します。
(1)人工的なバグを埋め込む行為は、「品質向上」の基本姿勢に反する
品質の高いプログラムを作りたいと思っているのに、プロジェクトマネジャーが無理やり人工バグを埋め込むという行為は、言語道断、神をも恐れぬ犯罪に思えてしまいます。エンジニアの良識に反し、心理的な抵抗感があります
(2)人工バグは、すぐに嗅ぎ分けられる
棚の本を並べる順番や机の上の物の置き方には個性があり、誰かが少しでもいじるとすぐに分かります。同様に、プログラマーには、「設計癖」や「コーディング癖」があり、他人が触ると0.5秒で「これはオレのコーディングスタイルじゃない!」と嗅ぎ分けられてしまいます(英語で“smell-out”と呼びます)
(3)人工バグの修正時に、誤って正常部分も変更してしまう危険性がある
人工バグも、もともと存在するバグと同様に、修正しなくてはなりません。この時に、間違って正常な部分も変更してしまう危険性があります。この確率は20%前後もあり、決して小さくありません。このバグは、人工バグがなければ、発生しなかったバグであり、まさに「余計なバグ」といえます。何とももったいない限りです
(4)最大の問題は「残存バグの推定値が、実際のバグ数よりもかなり小さい」
無理やり人工バグを埋め込んでバグ総数を求めても、この推定値の精度が高くありません。実際の値よりもかなり低く、研究によるとその推定値は、実際の値の40%前後になるそうです。これだけ低いと、「摘出目標値」としてプログラマーに示して、尻をたたくことには使えません。やはり、(2)の嗅ぎ分けにより、人工バグを簡単に検出できてしまうことが効いているのでしょう
以上の理由により、ソフトウェア版「池の中の魚」モデルは、アイデア自体は面白く、斬新ではありますが、すこぶる評判が悪く、「実際のプロジェクトで適用した!」という話は聞いたことがありません。
というわけで、次回、これの改訂版である「2チーム制モデル」を取り上げます。ベースは「池の中の魚」モデルですが、人工バグを埋め込んだりはしません。こちらは、かなり現実的な方式なので、実際のプロジェクトで適用している企業もあります。(次回に続く)
東海大学 大学院 組込み技術研究科 准教授(工学博士)
- イチから全部作ってみよう(34)マルチプログラミングとトランザクション
- イチから全部作ってみよう(33)「排他制御」をトイレのアナロジーで理解する
- イチから全部作ってみよう(32)PythonでSQLを実行してデータベースを操作する
- イチから全部作ってみよう(31)SQLを操作して実際にデータベースを作ってみる
- イチから全部作ってみよう(30)データベース操作の共通言語「SQL」を使ってみる
- イチから全部作ってみよう(29)3つのノート整理法からたどるRDBMSの基礎知識
- イチから全部作ってみよう(28)データ設計に必要なデータベースの基本事項
- イチから全部作ってみよう(27)「ACID」で示されるデータベースの4つの特性
- イチから全部作ってみよう(26)プログラムは「処理」と「データ」からできている
- イチから全部作ってみよう(25)脳内シミュレーションを駆使し画面設計書を完成させる
- イチから全部作ってみよう(24)設計フェーズの入り口「画面設計書」は紙芝居!?
- イチから全部作ってみよう(23)業務フロー図があれば“伏魔殿”も理解可能に
- イチから全部作ってみよう(22)シーケンス図によるモデリングで全体像を把握する
- イチから全部作ってみよう(21)ソフトウェア開発の見積もりは「KKD」がカギに
- イチから全部作ってみよう(20)生成AIを使えばイチから要求仕様書を作らずに済む
- イチから全部作ってみよう(19)今までの知識を総動員して要求仕様書を作成する
- イチから全部作ってみよう(18)生成AIと協力してプログラミングする時代がきた
- イチから全部作ってみよう(17)レビューは記録することで効率的に実施できる
- イチから全部作ってみよう(16)レビューは要求仕様書完成に向けた最後の関門
- イチから全部作ってみよう(15)テストの第一歩「セルフチェック」が大惨事を防ぐ
- イチから全部作ってみよう(14)異常系を組み込んだら仕様書が膨れ上がった!
- イチから全部作ってみよう(13)異常系への対策は「諦める」ことも肝要
- イチから全部作ってみよう(12)要求仕様書の異常系を階層構造を使って洗い出す
- イチから全部作ってみよう(11)たこ焼き屋模擬店の要求仕様書を抜け漏れなく作る
- イチから全部作ってみよう(10)トヨタとたこ焼き屋模擬店で理解する「機能分割」
- イチから全部作ってみよう(9)ジャンケンで理解する要求仕様書作成の難しさ
- イチから全部作ってみよう(8)発注側の要望を受けて始まる「ヒアリング」の例題
- イチから全部作ってみよう(7)正しい要求仕様書の第一歩となるヒアリングの手順
- イチから全部作ってみよう(6)要求仕様フェーズにおける開発の標準化やスパイラルモデルの有効性
- イチから全部作ってみよう(5)難題だらけの要求仕様フェーズにどう対処すべきか
- イチから全部作ってみよう(4)要求仕様フェーズに潜むさまざまな罠
- イチから全部作ってみよう(3)MINORIに学べ、全ての悪は要求仕様書から生まれる
- イチから全部作ってみよう(2)ワインのECサイトを作るためにイメージを深めよう
- イチから全部作ってみよう(1)ソフトウェア開発の大まかな流れを把握する
- 業務効率化の道具箱(16)上司の指示が「言語明瞭、意味不明」で困っています
- 業務効率化の道具箱(15)ツールを作るより難しい「業務改善の進め方」
- 業務効率化の道具箱(14)続・便利なツールと裏腹の「地雷」を踏まないために
- 業務効率化の道具箱(13)便利なツールと裏腹の「地雷」を踏まないために
- 業務効率化の道具箱(12)VBSなら面倒な環境構築なしで自作ツールを作れる
- 業務効率化の道具箱(11)VBAでグラフ描画が可能な自動集計アプリを作ってみよう
- 業務効率化の道具箱(10)VBAでさらに高機能な自動集計アプリを作ってみよう
- 業務効率化の道具箱(9)VBAで自動集計アプリを作ってみよう
- 業務効率化の道具箱(8)ツールがないならVBAで作ってみよう
- 業務効率化の道具箱(7)ターミナルソフト「RLogin」を使ってみよう
- 業務効率化の道具箱(6)Google Testを使ってみよう【その2】
- 業務効率化の道具箱(5)Google Testを使ってみよう【その1】
- 業務効率化の道具箱(4)VirtualBoxでUbuntu環境を構築しよう
- 業務効率化の道具箱(3)続・ショートカットキー活用、「技術の複利効果」で作業効率が上がりミスも減る
- 業務効率化の道具箱(2)ショートカットキーも積もれば山となる
- 業務効率化の道具箱(1)ソフト開発だけじゃないPCの業務効率を高める5つの道筋
関連キーワード
バグ | ソフトウェア | プロジェクトマネジャー | プログラム | デバッグ | ソースコード | 組み込み | 品質管理 | 組み込みソフトウェア | デスマーチ | 山浦恒央の“くみこみ”な話 | ソフトウェアテスト
関連記事
 あなたは「バグ」をどう数えていますか? 組み込みソフトウェアの品質管理を考える
あなたは「バグ」をどう数えていますか? 組み込みソフトウェアの品質管理を考える
あなたの現場では、ソフトウェアの品質管理の考え方をきちんと生かし切れていますか? MONOist編集部では組み込みソフトウェアの品質管理をテーマにしたゼミナール「組み込みソフトウェア開発で問われる品質力」を開催。組織における品質管理の考え方や、実際の開発現場におけるツールの活用・導入に関する事例などが披露された。 デスマーチ・プロジェクトでの正しい手の抜き方
デスマーチ・プロジェクトでの正しい手の抜き方
高機能・多機能化に加え、「品質向上」「コスト削減」「納期短縮」が強く求められる組み込み業界。小手先の対応では太刀打ちできない。- 連載記事「山浦恒央の“くみこみ”な話」
Copyright © ITmedia, Inc. All Rights Reserved.
組み込み開発の記事ランキング
- 日本再起の旗印となるか、国産マルチモーダルAI基盤「FRONTia」が始動
- サブ1nm半導体チップ技術を発表、性能最大50%向上
- TSMCの“Beyond 2nm”技術の現在地、「A14」で第2世代ナノシートトランジスタへ
- 大腸がんを低侵襲に治療できるESD、オリンパスが内視鏡ロボット技術で容易に
- 既設光ファイバーで450Tbps伝送に成功、周波数帯域幅を従来の4倍以上に拡大
- イチから全部作ってみよう(34)マルチプログラミングとトランザクション
- NVIDIAフアン氏が神田に現る――日本製造業巻き込む「ジャパンAI協業」祭り
- NVIDIAが「Jetson Thor」に新モジュール追加、高騰するメモリの使用量削減技術も
- インテグレーション地獄からの脱却:構造問題と「インテグレーター人権宣言」
- AIで脆弱性影響調査を自動化、管理工数を約70%削減
コーナーリンク



![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。