中国古文書の文字を少数の学習用データで認識する深層学習技術を開発:AIニュース
富士通は、中国の関連子会社である富士通研究開発中心が中国古文書の文字認識に用いる深層学習技術において、少数の学習用データでも高精度な文字認識ができる技術を開発したと発表した。
富士通は2017年2月21日、中国の関連子会社である富士通研究開発中心が中国古文書の文字認識に用いる深層学習技術において、少数の学習用データ(以下、教師データ)でも高精度な文字認識ができる技術を開発したと発表した。同技術を用いて古文書文字の電子化を促進し、中国古文書の公共利用と歴史研究などの学術の発展に貢献することが期待される。
同技術は、古文書の文字画像を文字と結び付けた教師データで学習させる深層学習の認識エンジンと、文字と結び付けていない2つの文字画像が同じか異なるかを学習する深層学習エンジンとを組み合わせて学習させるものだ。
まず、認識エンジンXを利用して文字画像データに仮の文字ラベルを付け、学習に利用する。次に、仮の文字ラベルを付けた文字画像から2つの文字ペアをランダムに生成し、認識エンジンY、Zに入力。2つの文字が同じか異なるかの結果だけを認識エンジンXに学習させる。これを繰り返し、認識エンジンXの学習が進むに従い、不正解の仮の文字ラベル数は減少し、認識精度が高まる。十分に学習させた認識エンジンXで認識を実行すれば、少数の教師データでも高い認識精度を発揮できる。
同技術を中国古文書文字認識用の中国敦煌古籍文献画像を用いたベンチマークに適用した。その結果、従来技術で得られる81%と同じ精度を、1文字当たり約70%少ない教師データ数で達成できた。また、同ベンチマークにおいて1文字当たり50個の教師データを用いて学習させた場合、従来の82%より高い88%の認識率を達成した。
中国には5000万冊以上の古文書が現存するが劣化や破損が懸念されている。そこで古文書のテキストデータ化が進められているが、現在は専門家が手作業で行っており、全ての古文書を電子化するためには多大な時間とコストが掛かる。また、従来の深層学習技術による文字認識では、文字画像と教師データを認識エンジンが学習していた。教師データの数が多いほど認識精度も高まるが、古文書文字への適用では教師データの数が不十分なことが課題となっていた。こうした背景を受けて、同技術が開発された。
同社は同技術を中国古文書電子化ソリューションとして展開していく。また、日本語や韓国語など、認識すべき文字の種類が多い用途に対しても認識精度を高めるのに有効だという。さらに、2018年度に同社のAI技術「Human Centric AI Zinrai」への活用を目指すとしている。
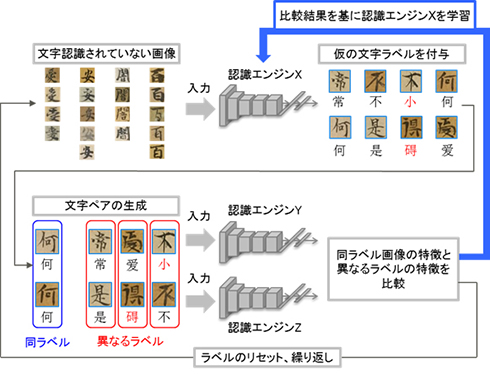 開発した文字認識方法の構成
開発した文字認識方法の構成
関連記事
 富士通のPC工場、勝利の方程式は「トヨタ生産方式+ICT活用」
富士通のPC工場、勝利の方程式は「トヨタ生産方式+ICT活用」
コモディティ化が進むPCで大規模な国内生産を続ける企業がある。富士通のPC生産拠点である島根富士通だ。同社ではトヨタ生産方式を基にした独自の生産方式「富士通生産方式」を確立し、効率的な多品種少量生産を実現しているという。独自のモノづくりを発展させる島根富士通を小寺信良氏が訪問した。 富士通PC開発における「モノを作らないモノづくり」
富士通PC開発における「モノを作らないモノづくり」
薄型軽量のノートPCやタブレット端末、スマートフォンなど、従来なかった仕様の機器開発においてCAEの活用は必須だ。 「日本版インダストリー4.0」のハブに! 富士通が次世代モノづくり戦略を発表
「日本版インダストリー4.0」のハブに! 富士通が次世代モノづくり戦略を発表
富士通は「次世代モノづくり」実現に向けた新たなビジョンと、それに対する新サービスの提供を発表した。富士通では2012年から「ものづくり革新隊」として、製造業として自社のノウハウと、提供するICTを組み合わせた製造業支援サービスを展開しており、今回はその流れをさらに拡大するものとなる。 モノに触れるだけで情報が得られる「グローブ型ウェアラブルデバイス」――富士通研
モノに触れるだけで情報が得られる「グローブ型ウェアラブルデバイス」――富士通研
富士通研究所は、保守・点検作業をタッチとジェスチャーで支援する「グローブ型ウェアラブルデバイス」を開発。NFCタグ検知機能と作業姿勢によらないジェスチャー入力機能により、端末操作をすることなく自然な動作だけで、ICTを活用した作業支援、結果入力などが行える。 メイドインジャパンの必勝パターンを読み解く
メイドインジャパンの必勝パターンを読み解く
2012年4月からスタートした「小寺信良が見たモノづくりの現場」では、10カ所の工場を紹介した。今回から2回にわたり、この連載で得た「気付き」から、「ニッポンのモノづくりの強み」についてまとめる。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
組み込み開発の記事ランキング
- 日本再起の旗印となるか、国産マルチモーダルAI基盤「FRONTia」が始動
- サブ1nm半導体チップ技術を発表、性能最大50%向上
- TSMCの“Beyond 2nm”技術の現在地、「A14」で第2世代ナノシートトランジスタへ
- 大腸がんを低侵襲に治療できるESD、オリンパスが内視鏡ロボット技術で容易に
- 既設光ファイバーで450Tbps伝送に成功、周波数帯域幅を従来の4倍以上に拡大
- イチから全部作ってみよう(34)マルチプログラミングとトランザクション
- NVIDIAフアン氏が神田に現る――日本製造業巻き込む「ジャパンAI協業」祭り
- NVIDIAが「Jetson Thor」に新モジュール追加、高騰するメモリの使用量削減技術も
- インテグレーション地獄からの脱却:構造問題と「インテグレーター人権宣言」
- AIで脆弱性影響調査を自動化、管理工数を約70%削減
コーナーリンク



![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。