ディープラーニング学習用ハードウェアの電力効率を向上させる回路技術を開発:人工知能ニュース
富士通研究所は、ディープラーニングの学習用ハードウェアの電力効率を向上させる回路技術を開発した。学習処理用データのビット幅を削減して電力効率を向上させつつも、認識性能は劣化しないため、クラウドやエッジサーバでの学習処理が可能になる。
富士通研究所は2017年4月24日、ディープラーニングの学習用ハードウェアの電力効率を向上させる回路技術を開発したと発表した。
今回開発したのは、演算に用いるデータのビット幅を削減した独自の数値表現と、ディープラーニングの学習演算の特徴をもとに、演算器の動きを随時解析しながら小数点の位置を自動的に制御する演算アルゴリズムによる回路技術だ。これにより、ディープラーニングの学習過程において、演算器のビット幅や学習結果を記録するメモリのビット幅を削減でき、その結果、電力効率が向上する。
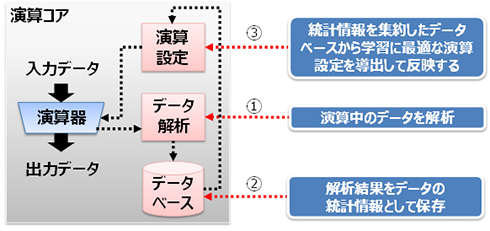 演算コアによる演算精度の向上 出典:富士通
演算コアによる演算精度の向上 出典:富士通電力効率は2つの側面から向上する。1つは、浮動小数点ではなく整数で演算することによる消費電力の削減だ。また、ビット幅を32ビットから8ビットにすることで、演算器やメモリの消費電力を約75%削減できる。
同技術を実装したディープラーニング学習用ハードウェアのシミュレーションで、手書き数字認識用のLeNetとMNISTのデータセットを用いて学習した。その結果、32ビット浮動小数点演算で98.90%の認識率が、16ビットで98.89%、8ビットでも98.31%と、ほぼ同等の認識率で学習可能であることを確認した。
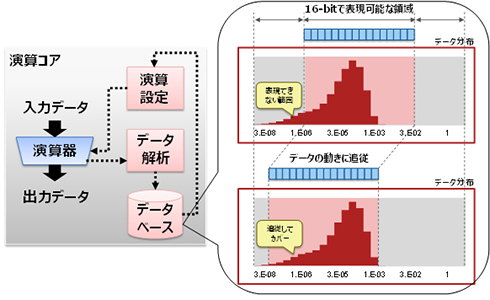 統計情報を用いた演算設定の最適化 出典:富士通
統計情報を用いた演算設定の最適化 出典:富士通ディープラーニングの学習プロセスで膨大な演算処理を実行するサーバなどのハードウェアでは、利用できる電力量で処理性能の上限が決まるため、電力効率の向上が課題だった。演算に用いるビット幅を減らすなどすれば電力効率は高まるが、演算に必要な精度が不足し、ディープラーニングの認識性能が劣化してしまうことがあった。
認識性能を落とさずに、電力効率を向上できる同技術により、ディープラーニングの学習処理を、クラウドサーバだけでなくデータが生成される場所に近いエッジサーバでも適用可能になる。
関連記事
 世界を変えるAI技術「ディープラーニング」が製造業にもたらすインパクト
世界を変えるAI技術「ディープラーニング」が製造業にもたらすインパクト
人工知能やディープラーニングといった言葉が注目を集めていますが、それはITの世界だけにとどまるものではなく、製造業においても導入・検討されています。製造業にとって人工知能やディープラーニングがどのようなインパクトをもたらすか、解説します。 富士通が量子コンピュータ超える新AI技術、グラフ構造データへの深層学習適用も
富士通が量子コンピュータ超える新AI技術、グラフ構造データへの深層学習適用も
富士通研究所が人工知能(AI)技術の最新成果を発表。「量子コンピュータを実用性で超える新アーキテクチャを開発」と「人やモノのつながりを表すグラフデータから新たな知見を導く新技術『Deep Tensor』を開発」の2件である。 「IoTの第2フェーズはまだ始まっていない」富士通山本正己氏
「IoTの第2フェーズはまだ始まっていない」富士通山本正己氏
10月7日まで開催されたCPS/IoT展「CEATEC JAPAN 2016」の基調講演で登壇した富士通 代表取締役会長の山本正己氏は「IoT活用の第2段階はまだ始まっていない」と述べている。 ディープラーニングの学習速度を「世界最速」に、富士通が開発
ディープラーニングの学習速度を「世界最速」に、富士通が開発
富士通研究所が複数GPUを用いて、ディープラーニングの学習速度を「世界最速」とする技術を開発した。AledNetでの評価ではGPU64台にて、単体の学習速度比で27倍という学習速度を達成した。 “実務に寄り添う”人工知能、富士通がクラウドサービスとして提供
“実務に寄り添う”人工知能、富士通がクラウドサービスとして提供
富士通は、人工知能(AI)関連技術を組み合わせてパッケージ化しクラウドサービスとして提供することを発表した。富士通でAI関連技術のみを切り出してサービスとして提供するのは初めて。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
組み込み開発の記事ランキング
- “Hello, World”と「Lチカ」の共通点
- Terra Drone、屋内点検用ドローン運用チームを熊本県の被災地へ派遣
- フィジカルAI時代のロボティクス新標準、安全性は「後付け」でなく「設計の核心」
- AIエージェントが車載アプリを動的に生成、イーソルがAIDVに向けた実験場を披露
- 富士通からC/C++およびJava対応のソースコード解析ツールの資産を取得
- “3つの頭脳”で80TOPSの処理性能を実現 AMDが語る「次世代AIチップ」戦略
- サブ1nm半導体チップ技術を発表、性能最大50%向上
- インフィニオンのヒューマノイド向け半導体戦略、2050年に3億台の市場を捉える
- ルネサスが高崎工場を閉鎖へ、かつてはSiCデバイス生産の計画も
- アマノの複数階清掃に対応した業務用ロボット掃除機に自律移動ソフトが採用
コーナーリンク



![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。