自律稼働デバイス向けの軽量な大規模視覚言語モデルを開発:人工知能ニュース
Preferred Networksは、自律稼働デバイス向けに軽量な大規模視覚言語モデル(VLM)「PLaMo 2.1-8B-VL」を開発した。言語情報と視覚情報を高度に統合して処理できるため、高度な画像理解が可能だ。
Preferred Networks(PFN)は2025年12月16日、自律稼働デバイス向けに軽量な大規模視覚言語モデル(VLM)「PLaMo 2.1-8B-VL」を開発したと発表した。
PLaMo 2.1-8B-VLは、80億パラメーターの軽量モデルでありながら、言語情報と視覚情報を高度に統合して処理できる。また、特定の作業タスクの分析や、画像認識を通じて異常を検知するといった複雑な判断を、デバイス単体で完結できる。従来のクラウド型AI(人工知能)では困難だった、低遅延が求められるロボットや自律移動体などのエッジ環境での運用を想定している。
PLaMo 2.1-8B-VLの開発に当たっては、大規模言語モデル「PLaMo 2.0-31B」をプルーニングと蒸留で軽量化した「PLaMo 2.1-8B」をベースモデルとして使用している。
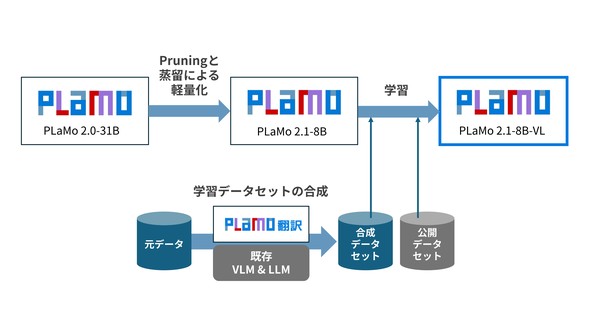 大規模言語モデルを軽量化した「PLaMo 2.1-8B」をベースモデルとして使用 出所:Preferred Networks
大規模言語モデルを軽量化した「PLaMo 2.1-8B」をベースモデルとして使用 出所:Preferred NetworksPLaMo 2.1-8B-VLは、位置関係の把握や属性認識、複合的な説明文の理解といった、基本性能を評価するベンチマークで高い性能を示した。
例えば、VQA(Visual Question Answering)ベンチマーク「JA-VG-VQA-500」では、「前方」という位置表現から、該当の場所にある物を特定できた。

テキストが示す人物や物体を画像から正確に特定する能力を評価する、Visual Groundingベンチマーク「Ref-L4」でも、位置関係を正しく理解し、指示通りに座標を出力できた。
 Visual Groundingベンチマークの例(位置関係理解)。犬の視線など複数の手掛かりから対象となる犬を特定[クリックで拡大] 出所:[写真]lasta29「Search and rescue dog, Japan Rescue Association」、[出典]Wikimedia Commons、[URL]https://commons.wikimedia.org/wiki/File:Search_and_rescue_dog,_Japan_Rescue_Association_(34690315563).jpg、[ライセンス]Creative Commons Attribution 2.0 Generic(CC BY 2.0、https://creativecommons.org/licenses/by/2.0/)、本記事に掲載するに当たりバウンディングボックス(緑枠)を追加している
Visual Groundingベンチマークの例(位置関係理解)。犬の視線など複数の手掛かりから対象となる犬を特定[クリックで拡大] 出所:[写真]lasta29「Search and rescue dog, Japan Rescue Association」、[出典]Wikimedia Commons、[URL]https://commons.wikimedia.org/wiki/File:Search_and_rescue_dog,_Japan_Rescue_Association_(34690315563).jpg、[ライセンス]Creative Commons Attribution 2.0 Generic(CC BY 2.0、https://creativecommons.org/licenses/by/2.0/)、本記事に掲載するに当たりバウンディングボックス(緑枠)を追加している今回の軽量視覚言語モデルの開発により、同社は物理的な世界で動作するフィジカルAIの実装をさらに加速させ、製造業やインフラ点検などの領域における自動化、省人化のニーズに応える。
なお、同社は実際の現場データによる技術検証や用途の具体化、社会実装に向けたフィードバックの取得を目的に、PLaMo 2.1-8B-VLのモニター企業を募集している。クラウドAPI経由で同モデルを2026年3月末まで無償提供し、技術検証の結果を性能向上や用途ごとのアプリケーション開発に生かす。
関連記事
 ロボットに生成AIを適用すると何ができるのか、課題は何なのか
ロボットに生成AIを適用すると何ができるのか、課題は何なのか
ロボット制御における生成AIの活用に焦点を当て、前後編に分けて解説する。前編では、生成AIの概要とロボット制御への影響について解説し、ROSにおける生成AI活用の現状について述べる。 PFNの次世代MN-CoreをRapidusが製造、さくらインターネットと国産AIインフラ構築
PFNの次世代MN-CoreをRapidusが製造、さくらインターネットと国産AIインフラ構築
Preferred Networks(PFN)、Rapidus、さくらインターネットの3社は、グリーン社会に貢献する国産AIインフラの提供に向けて基本合意を締結したと発表した。 ソニー・ホンダはVLMを用いたE2E方式のレベル4自動運転へ、車内を自由空間に
ソニー・ホンダはVLMを用いたE2E方式のレベル4自動運転へ、車内を自由空間に
ソニー・ホンダモビリティは「CES 2026」の出展に併せて、第1弾モデル「AFEELA 1」の最新状況を紹介するとともに、新モデルのプロトタイプ「AFEELA Prototype 2026」を初公開した。将来的にはVLMを用いたE2E方式のレベル4自動運転を実現し、車内をエンターテインメントを楽しむ自由な空間に変えるという。 NVIDIAがフィジカルAIのオープン展開を加速、自動運転向けで「Alpamayo」を公開
NVIDIAがフィジカルAIのオープン展開を加速、自動運転向けで「Alpamayo」を公開
NVIDIAは「CES 2026」の開催に合わせて、フィジカルAI(人工知能)の代表的なアプリケーションである自動運転技術とヒューマノイド向けのオープンソースAIモデルを発表した。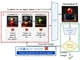 パナソニックHDが画像生成AIの効率を5倍に、一人称視点映像からの未来予測も
パナソニックHDが画像生成AIの効率を5倍に、一人称視点映像からの未来予測も
パナソニックHDが画像生成AI技術の新たな成果を発表。推論時にAIが自らの生成結果を振り返って改善する「Reflect-Dit」と、一人称視点の映像や頭部軌道から現在の動作推定や未来の動作予測を可能にする「UniEgoMotion」の2つである。 NVIDIAがロボットシミュレーション用物理モデル「Newton」のβ版を公開
NVIDIAがロボットシミュレーション用物理モデル「Newton」のβ版を公開
NVIDIAは、Google DeepMind、Disney Researchと共同開発してきたロボットシミュレーション用物理モデル「Newton Physics Engine」のβ版をリリースしたと発表した。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
組み込み開発の記事ランキング
- “Hello, World”と「Lチカ」の共通点
- Terra Drone、屋内点検用ドローン運用チームを熊本県の被災地へ派遣
- フィジカルAI時代のロボティクス新標準、安全性は「後付け」でなく「設計の核心」
- AIエージェントが車載アプリを動的に生成、イーソルがAIDVに向けた実験場を披露
- 富士通からC/C++およびJava対応のソースコード解析ツールの資産を取得
- “3つの頭脳”で80TOPSの処理性能を実現 AMDが語る「次世代AIチップ」戦略
- サブ1nm半導体チップ技術を発表、性能最大50%向上
- インフィニオンのヒューマノイド向け半導体戦略、2050年に3億台の市場を捉える
- ルネサスが高崎工場を閉鎖へ、かつてはSiCデバイス生産の計画も
- アマノの複数階清掃に対応した業務用ロボット掃除機に自律移動ソフトが採用
コーナーリンク



![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。