
パナソニックHDがマルチモーダル生成AIで新たな成果、学習データ量を60分の1に:人工知能ニュース(2/2 ページ)
生成AIチューニング技術「Diffusion-KTO」との組み合わせも
これらの工夫により、生成の過程で3つのモーダルの異なるデータ特徴を「アテンション機構」によって直接結び付けることで、従来手法のように各モーダルの特徴を平均するだけでは得られないデータ間の複雑な関係を学習できるようになった。

性能評価に用いたOmniFlowは以下のプロセスで作成した。まず、画像生成AIである「Stable Diffusion 3」を用いて「テキスト→画像」の学習を行い、この「テキスト→画像」のモデルのテキスト処理部に音声処理を加えて「テキスト→音」の学習を行った。その後、2つのモデルのテキスト処理部のパラメーターを平均して1つのテキスト処理部として扱うことで、テキストと画像、音の3モーダルの入出力が可能なモデルを作成した。最後に、このモデルに3つのモーダルが全てそろったペアデータを使って学習することで、Any-to-Anyに対応するマルチモーダル生成AIであるOmniFlowが得られる。OmniFlowを得る最後の学習プロセスに必要となる3つのモーダルが全てそろったペアデータの量は、ここまで全ての学習プロセスに用いたデータ量の6%に抑えられている。

このOmniFlowを用いて、「テキスト→画像」と「テキスト→音」のデータ生成を行ったところ、既存のマルチモーダル生成AIだけでなく単一モーダル特化型生成AIと比べても高品質のデータを生成できた。また、学習データ量については、既存のマルチモーダル生成AIと比べると60分の1まで削減できている。
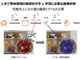
 「OmniFlow」のマルチモーダルでのデータ生成性能。左側の表中の赤色の点線で示したImagesを基にUnidiff(2B)とOmniFlow(30M)の学習データ量を比較すると約60分の1になっている[クリックで拡大] 出所:パナソニックHD
「OmniFlow」のマルチモーダルでのデータ生成性能。左側の表中の赤色の点線で示したImagesを基にUnidiff(2B)とOmniFlow(30M)の学習データ量を比較すると約60分の1になっている[クリックで拡大] 出所:パナソニックHDOmniFlowの用途としては、音声認識の現場適用向けに雑音/環境音データを生成するなど、新たな現場でのデータ収集コストを抑えてAI適用先を拡大することなどが検討されている。

パナソニックHDは、データから実装まで一貫したAI開発プロセスの高度化に取り組んでおり、これまでに学習データのアノテーションを効率化するマルチモーダル基盤モデル「HIPIE」や「SegLLM」、FastLabelとの協業で構築したアノテーションプラットフォーム、生成AIチューニング技術「Diffusion-KTO」などを開発している。これらのうちDiffusion-KTOは、OmniFlowとの組み合わせにより商品や現場数が多い領域に対するデータ生成の活用に適しているという。

なお、OmniFlowの研究開発成果は、2025年6月11〜15日に米国ナッシュビルで開催予定のAI/コンピュータビジョンのカンファレンス「CVPR 2025」に採択された。
関連記事
 パナソニックが画像認識マルチモーダル基盤を刷新、HIPIEからSegLLMへ
パナソニックが画像認識マルチモーダル基盤を刷新、HIPIEからSegLLMへ
パナソニック ホールディングスはテキストと参照画像を用いて未学習の物体も指示できる対話型セグメンテーション技術を開発した。 パナソニックHDがAI開発コスト10分の1へ、画像生成AIのパーソナライズをN倍効率化
パナソニックHDがAI開発コスト10分の1へ、画像生成AIのパーソナライズをN倍効率化
パナソニック R&D カンパニー オブ アメリカとパナソニック ホールディングスは、ユーザーの「Good(いいね)」や「Bad(嫌い)」といったバイナリフィードバックで生成モデルを調整し、ユーザーの目的や好みに合わせた画像を効率よく生成できる画像生成AI「Diffusion-KTO」を開発した。 AI活用の障壁であるアノテーションの自動化でパナソニックHDとFastLabelが協業
AI活用の障壁であるアノテーションの自動化でパナソニックHDとFastLabelが協業
パナソニックHDとFastLabelは、パナソニックグループのAI開発の効率化を目的とし協業を行う。AIプロセス全体の効率化とともに、パナソニックHDが開発するマルチモーダル基盤モデル「HIPIE」とFastLabelのData-Centric AIプラットフォームを統合し、自動アノテーションモデルとして構築する。 画像認識AIの現場実装作業が10分の1に、パナソニックHDが汎用基盤モデルを開発
画像認識AIの現場実装作業が10分の1に、パナソニックHDが汎用基盤モデルを開発
パナソニックHDは、画像認識AIを現場実装する際に必要なアノテーションなどの作業負荷を大幅に削減可能な画像認識向けマルチモーダル基盤モデル「HIPIE」を開発した。 構造改革の中、パナソニックHDがR&Dで注力する領域と凍結する領域の考え方
構造改革の中、パナソニックHDがR&Dで注力する領域と凍結する領域の考え方
パナソニック ホールディングス グループCTOである小川立夫氏が報道陣の合同取材に応じ、研究開発(R&D)領域における2024年度の成果を紹介するとともに、構造改革を踏まえた技術開発部門としての考え方を説明した。 AIで勝つ企業へ、パナソニックグループは2035年までにAI関連売上30%を宣言
AIで勝つ企業へ、パナソニックグループは2035年までにAI関連売上30%を宣言
パナソニック ホールディングス グループCEOの楠見雄規氏が、「CES 2025」のオープニングキーノートに登壇した。本稿では、このオープニングキーノートとパナソニックブースの展示内容を前後編に分けて紹介する。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
組み込み開発の記事ランキング
- “Hello, World”と「Lチカ」の共通点
- インフィニオンのヒューマノイド向け半導体戦略、2050年に3億台の市場を捉える
- サブ1nm半導体チップ技術を発表、性能最大50%向上
- Terra Drone、屋内点検用ドローン運用チームを熊本県の被災地へ派遣
- AIエージェントが車載アプリを動的に生成、イーソルがAIDVに向けた実験場を披露
- フィジカルAI時代のロボティクス新標準、安全性は「後付け」でなく「設計の核心」
- 富士通からC/C++およびJava対応のソースコード解析ツールの資産を取得
- MediaTek製SoCを搭載するSOMの事業を拡大、エッジAI開発の支援に向け
- “3つの頭脳”で80TOPSの処理性能を実現 AMDが語る「次世代AIチップ」戦略
- 上面放熱構造により高放熱と高耐圧を両立したSiC-MOSFETの新パッケージ
コーナーリンク



![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。