
産総研の最新スパコン「ABCI 3.0」の狙いや展望――総括研究主幹の高野氏に聞く:AIとの融合で進化するスパコンの現在地(6)(2/3 ページ)
ChatGPTの登場を契機にABCIの利用にも大きな変化が
―― AIの研究開発を促進することや、民間への技術の橋渡しを目的にABCIを構築したというお話でしたが、利用はすぐに広まったのでしょうか。
高野氏 ABCI 1.0が運用を始めた当初は産総研内と外部利用が半々程度でしたが、徐々に民間にも広がって、ABCIの利用事例ページに載っているように、大企業やIT企業だけではなくて、AIのスタートアップや、ITとは直接関係のない企業の利用も増えていきました。ユーザーの増加とともに計算リソースが不足するようになり、ABCI 1.0はそのままに、2021年5月にNVIDIA A100 Tensorコアを960基増設しました。このシステムを「ABCI 2.0」と呼んでいます。ABCI 2.0の最後の方では外部ユーザーが全体の8割を占めるまでになりました。
―― ABCI 2.0の1年半後の2022年11月にChatGPTが登場します。生成AIはABCIにどのようなインパクトをもたらしましたか?
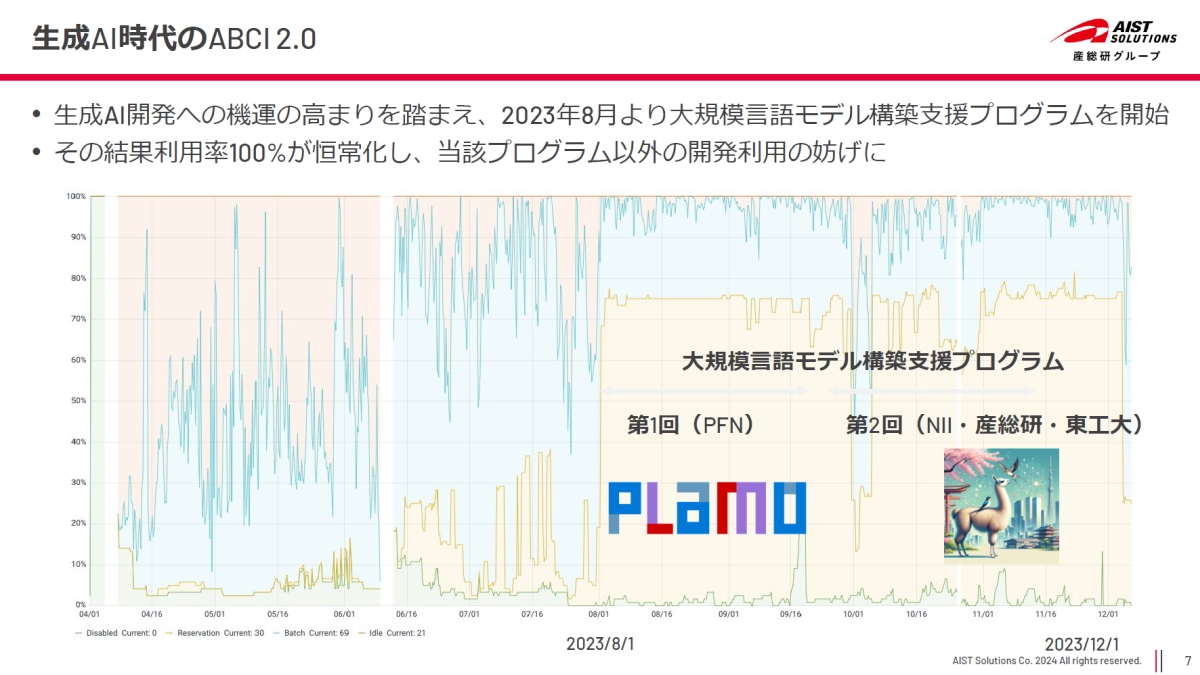
高野氏 使われ方が一気に変わりましたね。それまではGPUが8基あれば完結するぐらいの使い方がメインで、複数台のサーバを使って分散機械学習をする民間のユーザーは限られていました。それが生成AIが出てきてからは、あるだけGPUを欲しい、みたいなことを言われるようになりました。とはいえ全ての要望を受け入れるのは難しいので、生成AIのLLM(大規模言語モデル)の学習に特化した「大規模言語モデル構築支援プログラム」を2023年度と2024年度に公募して、採択した人たちに優先的に使ってもらう取り組みを実施し、Preferred Networksの「PLaMo」、東工大と産総研の「Swallow」、ELYZAの日本語LLMなどの成果を得ています。ただ、そのシワ寄せは当然あって、他のユーザーからするとジョブを投げても待ち時間がすごく長くて、いつまでたってもジョブが実行されない、困ります、というクレームが増えてきたんです(連載第5回の図4を参照)。
―― それでABCI 3.0の話が生まれてきたと。
高野氏 2023年5月11日に政府のAI戦略会議(第1回)が開催されて、ChatGPTをはじめとする生成AIの台頭も背景に欧米や中国のAIの研究開発に劣後しないように計算リソースの拡充をなんとかしなくてはいけないという話が発端でした。じゃあ産総研で整備していきましょうという方針が示されてからは、あっという間に話が進みました。
ABCI 2.0の稼働をほぼ止めずにABCI 3.0に切り替え
―― ABCI 3.0のシステムのアーキテクチャはどのように構想したのですか。
高野氏 1台のサーバにできるだけ多くのGPUを搭載した「ファットノード」でシステムを構成した方がトレーニング性能は上がりますので、NVIDIAのレファレンスアーキテクチャも参考にしながら、全体コストやネットワーク帯域やストレージとのバランスを考慮して仕様をまとめていきました。
 ABCI 3.0の計算ノード。NVIDIA H200 Tensorコアを8基搭載できるHPE Cray XD670が採用され、ABCI 2.0に比べて、半精度(FP16/BF16)で約7倍、単精度(FP32/TF32)で約13倍の性能向上を実現している[クリックで拡大] 出所:産総研「ABCI 3.0記者見学会」
ABCI 3.0の計算ノード。NVIDIA H200 Tensorコアを8基搭載できるHPE Cray XD670が採用され、ABCI 2.0に比べて、半精度(FP16/BF16)で約7倍、単精度(FP32/TF32)で約13倍の性能向上を実現している[クリックで拡大] 出所:産総研「ABCI 3.0記者見学会」 75PBのストレージを装備する。LLMの開発ではトレーニング用の入力データやトレーニング中のチェックポイントなど多くの大容量ファイルを扱うため、ボトルネックを生まないように性能の高いオールフラシュで構成した[クリックで拡大] 出所:産総研 「ABCI 3.0記者見学会」
75PBのストレージを装備する。LLMの開発ではトレーニング用の入力データやトレーニング中のチェックポイントなど多くの大容量ファイルを扱うため、ボトルネックを生まないように性能の高いオールフラシュで構成した[クリックで拡大] 出所:産総研 「ABCI 3.0記者見学会」入札を経てベンダーが決まったのが2024年5月末で、そこから半年ぐらいで運用までこぎ着けることが目標でした。一方でABCI 2.0のユーザーもいますので、計算能力を維持しながら切り替えるにはどうしたらいいんだろうと。パズルみたいなテーマだったんですけど、まず、ABCI 2.0と同じ0.85EFLOPSが得られるようにABCI 3.0の一部のハードウェア(サーバノード108台)をデータセンターの空きスペースに入れて、ユーザーがそちらに移行したらABCI 2.0を撤去して、空いたスペースにABCI 3.0の残りを入れようと。運用中の計算機室で工事しても大丈夫なんだろうかなどいろいろ不安はあったんですけど、関係者の皆さんが知恵を絞ってくれて、2024年11月中旬には試験運用をスタートして、2025年1月20日に一般公開ができました。
Copyright © ITmedia, Inc. All Rights Reserved.
組み込み開発の記事ランキング
- “Hello, World”と「Lチカ」の共通点
- インフィニオンのヒューマノイド向け半導体戦略、2050年に3億台の市場を捉える
- サブ1nm半導体チップ技術を発表、性能最大50%向上
- Terra Drone、屋内点検用ドローン運用チームを熊本県の被災地へ派遣
- AIエージェントが車載アプリを動的に生成、イーソルがAIDVに向けた実験場を披露
- フィジカルAI時代のロボティクス新標準、安全性は「後付け」でなく「設計の核心」
- 富士通からC/C++およびJava対応のソースコード解析ツールの資産を取得
- MediaTek製SoCを搭載するSOMの事業を拡大、エッジAI開発の支援に向け
- “3つの頭脳”で80TOPSの処理性能を実現 AMDが語る「次世代AIチップ」戦略
- 上面放熱構造により高放熱と高耐圧を両立したSiC-MOSFETの新パッケージ
コーナーリンク



{kind=link}
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。