
PFNが深層学習速度で世界最速に、「ChainerMN」のスケールアウト性能を証明:人工知能ニュース
Preferred Networks(PFN)は、深層学習(ディープラーニング)の学習速度で世界最速を実現したと発表した。2017年9月から稼働を開始している国内民間最大規模のプライベートスーパーコンピュータ「MN-1」と、独自の並列分散学習パッケージ「ChainerMN」によって実現したという。
Preferred Networks(PFN)は2017年11月10日、深層学習(ディープラーニング)の学習速度で世界最速を実現したと発表した。同年9月から稼働を開始している国内民間最大規模のプライベートスーパーコンピュータ「MN-1」と、独自の並列分散学習パッケージ「ChainerMN」によって実現したという。
深層学習の速度についてはさまざまな基準があるが、今回の成果は、広く利用されている画像分類データセットであるImageNetと、画像認識の分野で多用されるニューラルネットワークのモデルであるResNet-50を用いた学習を基準としている。
MN-1は、NVIDIAの「Tesla P100 GPU」を1024基搭載しており、理論上のピーク性能は4.7ペタフロップス(1ペタフロップスは毎秒1000兆回の浮動小数点演算が可能であることを表す)とされている。このMN-1上でChainerMNを用いて深層学習を行ったところ15分で完了したという。従来の研究報告では、インテルの「Xeon Platinum 8160」を1600台使用した31分が最速だったので、2倍以上の速度を達成したことになる。
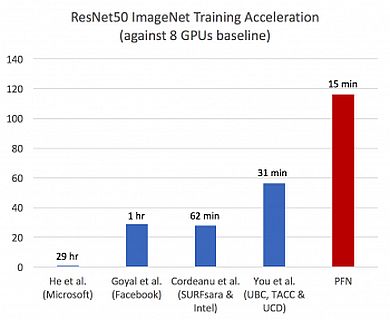 ImageNetとResNet-50による学習速度の比較。従来は31分が最速だったが、PFNは「MN-1」と「ChainerMN」で15分に短縮した 出典:PFN
ImageNetとResNet-50による学習速度の比較。従来は31分が最速だったが、PFNは「MN-1」と「ChainerMN」で15分に短縮した 出典:PFN深層学習モデルをスーパーコンピュータで並列分散処理する場合、バッチサイズが大きくなることやCPUとGPU間の通信のオーバーヘッドなどが影響し、CPUやGPUの数に比例してモデルの精度や学習速度が伸びていかないという課題がある。
今回の成果は、ChainerMNがGPUの数にほぼ比例して学習速度を高められる特徴(スケールアウト性能)を、より大規模な1024GPUのMN-1を使って実証したことになる。PFNは、今回の成果を活用して「大規模な深層学習を必要とする交通システム、製造業、バイオヘルスケア分野での研究開発をより一層加速させていく」としている。
関連記事
 世界を変えるAI技術「ディープラーニング」が製造業にもたらすインパクト
世界を変えるAI技術「ディープラーニング」が製造業にもたらすインパクト
人工知能やディープラーニングといった言葉が注目を集めていますが、それはITの世界だけにとどまるものではなく、製造業においても導入・検討されています。製造業にとって人工知能やディープラーニングがどのようなインパクトをもたらすか、解説します。 AI×IoTのブレークスルーを生み出すPreferred Networks、原動力は成長と多様性
AI×IoTのブレークスルーを生み出すPreferred Networks、原動力は成長と多様性
ベンチャー企業のPreferred Networks(PFN)は、時代に先駆けてAIとIoTに着目することで一気に業容を拡大している。同社の原動力になっているのは、創業精神として今も続く「常に新しく技術を取り込んでいく成長」と「多様性」だ。 Windows版Chainerのビルド済みバイナリを配布へ、「国内でのインパクト大きい」
Windows版Chainerのビルド済みバイナリを配布へ、「国内でのインパクト大きい」
Preferred Networks(PFN)と日本マイクロソフトがディープラーニングのコミュニティー「Deep Learning Lab」のキックオフイベントを開催。「Windows」や「Azure」といったマイクロソフト製品で、PFNのディープラーニングソリューションを使いやすくしていく方向性を示した。 深層学習研究用のプライベートスパコンが稼働開始、民間では国内最大規模
深層学習研究用のプライベートスパコンが稼働開始、民間では国内最大規模
Preferred Networksは、深層学習を研究開発するためのプライベートスーパーコンピュータの稼働を開始した。計算ノードにNVIDIA製のTesla P100 GPUを1024基搭載し、民間企業の計算環境としては、国内最大規模のスーパーコンピュータとなる。 トヨタがPFNに105億円を追加出資、モビリティ向けAI技術の研究開発を加速
トヨタがPFNに105億円を追加出資、モビリティ向けAI技術の研究開発を加速
トヨタ自動車とPreferred Networks(PFN)は、自動運転技術をはじめモビリティ事業分野におけるAI(人工知能)技術の共同研究・開発の加速を目的に、トヨタ自動車がPFNに約105億円を追加出資することで合意した。 現場志向のIoT基盤「FIELD system」が運用開始、稼働監視などを年間100万円で
現場志向のIoT基盤「FIELD system」が運用開始、稼働監視などを年間100万円で
ファナックとシスコシステムズ、ロックウェル オートメーション ジャパン、Preferred Networks、NTTグループ3社は、2016年4月に開発に着手した製造現場向けのIoTプラットフォーム「FIELD system」の国内サービスを開始した。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
組み込み開発の記事ランキング
- “Hello, World”と「Lチカ」の共通点
- インフィニオンのヒューマノイド向け半導体戦略、2050年に3億台の市場を捉える
- サブ1nm半導体チップ技術を発表、性能最大50%向上
- Terra Drone、屋内点検用ドローン運用チームを熊本県の被災地へ派遣
- AIエージェントが車載アプリを動的に生成、イーソルがAIDVに向けた実験場を披露
- フィジカルAI時代のロボティクス新標準、安全性は「後付け」でなく「設計の核心」
- 富士通からC/C++およびJava対応のソースコード解析ツールの資産を取得
- MediaTek製SoCを搭載するSOMの事業を拡大、エッジAI開発の支援に向け
- “3つの頭脳”で80TOPSの処理性能を実現 AMDが語る「次世代AIチップ」戦略
- 上面放熱構造により高放熱と高耐圧を両立したSiC-MOSFETの新パッケージ
コーナーリンク



![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。