マルチコアの処理単位並列化手法:組み込みマルチコア進化論(4)(2/2 ページ)
タスク並列化は、処理単位で分割を検討した際に有効な並列化手法で、手順並列法とも呼ばれています。処理をタスク単位に分割し、そのタスクを並列に動作させることにより処理の高速化を図ります。
まず、処理をタスクに分割し、各コアに割り当てます。各コアの行う処理は「ワーカ」と呼ばれます。そして、処理が行われる順番などの情報は「タスクキュー」に設定します。各ワーカはタスクキューを参照して処理を行い、タスクキューが終了するまで処理が実行されます。データ並列化は、データの数が明確でないと分割を行うことが困難ですが、タスク並列化は、データ数が明確でなくても実行を行うことが可能です。
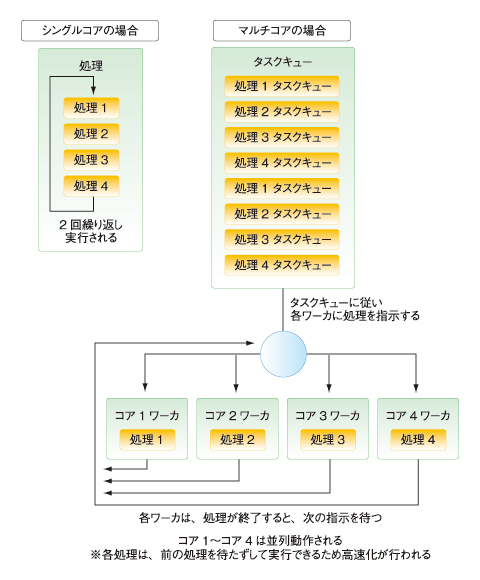 図5 タスク並列化手法
図5 タスク並列化手法同期タイミングの検討
同期タイミングについては、リアルタイムOSのタスク間通信と似ていますので、詳しくは、そちらを参考してください。今回は、「ロック/アンロック」、「fork/join」について説明します。
ロック/アンロックとは、「使用可能/使用禁止」のような2種類のフラグのようなものです。複数のユーザーが資源を共有する際に、同時にアクセスすることで発生する不具合を防ぐため、排他制御を行います。各コアのタスクは、その値を参照してハードウェア資源を使って良いかどうかを判断し、資源を使う場合には、ロックして資源「使用中」であることを他のコアのタスクに知らせます。
例えば、各コアのタスクでハードウェア資源を使う際には、ロック状態を参照し、使用可能であればそれを使用禁止(ロック)にしたうえでハードウェア資源を利用します。別のコアのタスクは資源の解放を確認できるまで待ち状態となります。別のコアのタスクは、使用中のタスク処理が終了した際に使用可能(アンロック)にすることで、資源が使用可能となります。
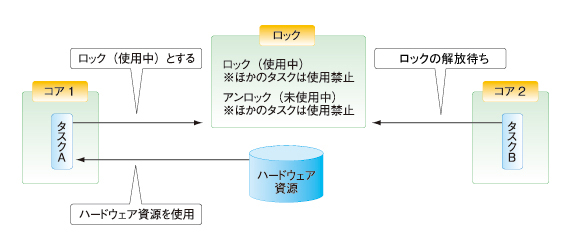 図6 ロック/アンロックの仕組み
図6 ロック/アンロックの仕組みfork(フォーク)とjoin(ジョイン)は、マスタースレッドと、スレーブスレッドの関係にあります。forkはマスタースレッドから複数のスレードスレッドを生成し、並列実行を開始します。そして、joinはすべてのスレーブスレッドが完了するまで同期する処理です。つまり、マスタースレッドは、並列で動作した処理がすべて終了させるまで待ち、再び動作するようになります。
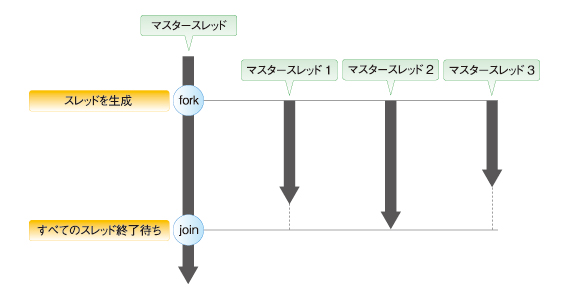 図7 fork/joinとは
図7 fork/joinとはデータ依存性の除去を検討
次にデータ依存性の除去について説明します。データの依存性は、データの書き込みと、読み込みの関係によっては、除去することができます。ただし、はじめにデータについて双方のコアから書き込みが行われずに読み込みのみを行っている場合は、どちらのコアからどのタイミングで処理が行われていても、データに依存関係がないので、データ依存性には含まれません。
データ依存性の種類としては、フロー依存/逆依存/出力依存の3種類が存在します。フロー依存とは、書き込んだデータをその後で読みだすものです。逆依存はフロー依存と逆で、読み込み後に書き込みを行うものです。そして出力依存は書き込みが行われた後に、また別の値が書き込まれる場合です。
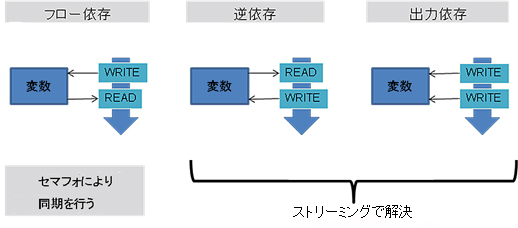 図8 データ依存性の種類
図8 データ依存性の種類フロー依存の場合は、書き込みが行われる前に、読み込みが行われると値が変化してしまうため、アクセス順序が変更となってはいけません。その際はセマフォなどにより同期をとる必要があります。また、逆依存と出力依存については、一般的には、それぞれ違う変数を使用する事を検討する「リネーミング」で解決ができますが、それらについては、処理内容を確認し、問題が無いかどうかを検討する必要があります。
おわりに
今回は、処理単位並列化手法を紹介しました。将来マルチコアの時代は、絶対に来ます。「100年に一度の不況」といわれるこの世の中で、今までは時間が取れなくて一歩を踏み出せずにいた人、「ピンチをチャンス」に変えるために、一緒にマルチコアを考えて行きましょう。
ご意見、ご質問がある方は件名を「マルチコア並列化手法の件」として、メールアドレスinfo@zipc.comまでご連絡ください。また、参考ホームページはhttp://www.zipc.com/support/rre/multicore/になります。よろしくお願いいたします。
次回もお楽しみに。(次回に続く)
関連記事
Copyright © ITmedia, Inc. All Rights Reserved.
組み込み開発の記事ランキング
- “Hello, World”と「Lチカ」の共通点
- インフィニオンのヒューマノイド向け半導体戦略、2050年に3億台の市場を捉える
- サブ1nm半導体チップ技術を発表、性能最大50%向上
- Terra Drone、屋内点検用ドローン運用チームを熊本県の被災地へ派遣
- AIエージェントが車載アプリを動的に生成、イーソルがAIDVに向けた実験場を披露
- フィジカルAI時代のロボティクス新標準、安全性は「後付け」でなく「設計の核心」
- 富士通からC/C++およびJava対応のソースコード解析ツールの資産を取得
- MediaTek製SoCを搭載するSOMの事業を拡大、エッジAI開発の支援に向け
- “3つの頭脳”で80TOPSの処理性能を実現 AMDが語る「次世代AIチップ」戦略
- 上面放熱構造により高放熱と高耐圧を両立したSiC-MOSFETの新パッケージ
コーナーリンク



![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。