マルチコアの処理単位並列化手法:組み込みマルチコア進化論(4)(1/2 ページ)
今回は、処理単位で並列化を検討することで処理の高速化を図る「処理単位並列化手法」を紹介します
はじめに
前回は、マルチコア分割(並列化)手法を読者の皆さんと進化させていくというテーマで、「繰り返し処理におけるデータの並列化手法」を紹介しました。今回は、処理単位で並列化を検討することで高速化を図る「処理単位並列化手法」を紹介します。
本連載の第1回でもマルチコア環境並列化手法の分類を簡単に説明しましたが、下表の赤枠内が、処理単位並列化に関する部分であり、今回説明対象となる部分です。
 表 マルチコア環境並列化手法の分類
表 マルチコア環境並列化手法の分類処理単位並列化における概要
ここでは、処理単位並列化の概要について説明します。図1にありますように、まずは、処理単位における分割ポイントを決定します。次に、分割により発生した依存関係の検討、タスク並列化などの処理の並列化、同期タイミングの検討、そして最後にデータ依存性が除去できるものに関しては、データ依存性の除去を行います。これらの処理を繰り返し行うことによって、機能(処理)の並列化を行います。
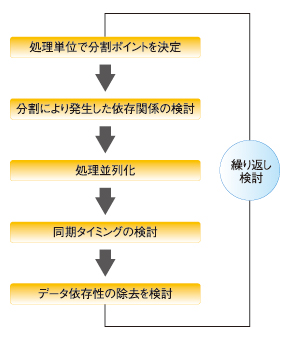 図1 処理単位並列化の手順
図1 処理単位並列化の手順処理単位で分割ポイントを決定
まず、処理の分割を行うためには、分割ポイントを決定する必要があります。前回紹介した繰り返し処理の並列化では、ループ(for)構文に着目するため着目ポイントは明確でしたが、今回の分割手法ではまず分割ポイントを見つけることが困難となります。それは、設計した人の指針と、ソフトウェアの構造などを理解して分割するポイントを見つける必要があるためです。それには参考となるドキュメントが有効になりますので以下に参考となるドキュメントを紹介します。
- コンポーネント図
- 状態遷移表(STM:State Transition Matrix)
- ソフトウェアの構造を現したドキュメント
- 機能説明書(仕様書など)
- 抽象度の高いモデル(UMLなど)
オブジェクト指向設計で「コンポーネント化」されて設計されたものは、そもそもコンポーネントとして、他とのインターフェイスが明確になっています。そのため、依存関係が明確で分割ポイントが決定しやすくなります。
また、本連載の第2回「マルチコア環境における並列化有効ポイント」で紹介した状態遷移表(STM:State Transition Matrix)で設計を行ったものであれば、状態とイベントと処理が明確であるため、比較的容易に分割ポイントを決定しやすくなります。さらに、「ソフトウェアの構造を現したドキュメント」、「仕様書などの機能説明」、「UMLなどの抽象度の高いモデル」など抽象度の高いドキュメントを参考にして、分割ポイントを決定します。
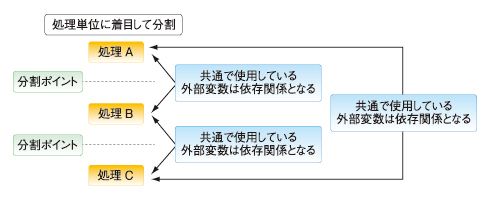 図2 処理単位に着目した分割ポイント
図2 処理単位に着目した分割ポイントC言語ソースコードで処理を分割する際には、main()関数などから、上位関数より分割ポイントの検討を行います。以下に考え方の例を記します。
void main() {
sub1(); //処理A
<★分割ポイント>
sub2(); //処理B
<★分割ポイント>
sub3(); //処理C
}
void sub1() {
. . . //Aの処理
}
void sub2() {
. . . //Bの処理
}
void sub3() {
. . . //Cの処理
}
依存関係の検討
ここでは、処理単位並列化手法で発生する依存関係について説明します。分割を行うと、それぞれのコアから同じ外部変数をアクセスした際に処理順序が変更になるため、問題が発生するケースがあります。
まず、逐次処理で、処理1→処理2→処理3と順番に実行させている処理を、処理1をコア1に、処理2と処理3をコア2に割り当てたとします。その際、処理1と処理3は並列に実行されるため、処理2が処理2よりも先に実行されてしまう可能性があります。よって、共有メモリに対して処理1で書きこんだ後に、処理2で書きこんだ値が上書きされ、値を特定できなくなるケースがあります。つまり、マルチコア化で並列化処理が行われると、処理順序が変化するタイミングが発生し、このような問題が発生してしまいます。
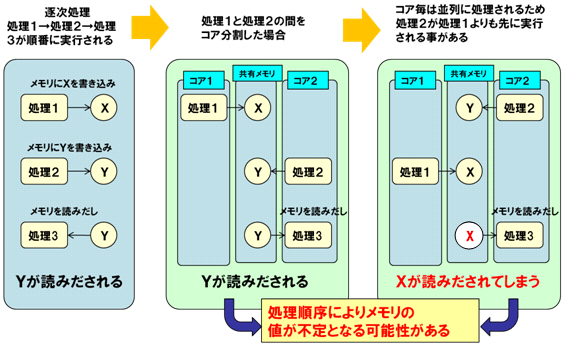 図3 分割により発生する依存関係の問題
図3 分割により発生する依存関係の問題こうした処理順序の問題が発生するため、処理を分割する際には、依存関係を検討する必要があります。そのためには、どの関数がどの外部変数をアクセスしているかを明確にし、依存関係がある部分は、処理順序の問題を検討する必要があります。また、同期を取るには処理待ち時間が必要となるため、なるべく依存関係の少ない部分で分割をする必要があります。ここでは、関数ごとにどの外部変数のアクセスがあるかを明確にして、どこで分割を行うかを検討します。
図4はマルチコア分割検討ツールβ版の画面です。縦列に関数名、横列に外部変数の一覧が表示されています。そして、コア分割を行った際に、どこに依存関係が発生するかを明確にするために、各関数がアクセスしている外部変数の位置に○が表示されています。
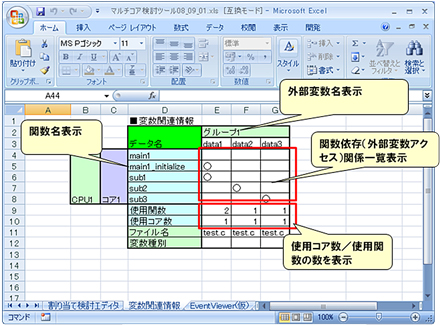 図4 マルチコア分割検討ツールβ版の画面(提供:キャッツ)
図4 マルチコア分割検討ツールβ版の画面(提供:キャッツ)タスクの並列化
逐次処理を並列処理に変更する手法には「データ並列化」「パイプライン並列化」「タスク並列化」の3通りがあります。「データ並列化」と「パイプライン並列化」については、本連載の第3回で説明しているため、今回は、「タスク並列化」について説明します。
Copyright © ITmedia, Inc. All Rights Reserved.
組み込み開発の記事ランキング
- “Hello, World”と「Lチカ」の共通点
- インフィニオンのヒューマノイド向け半導体戦略、2050年に3億台の市場を捉える
- サブ1nm半導体チップ技術を発表、性能最大50%向上
- Terra Drone、屋内点検用ドローン運用チームを熊本県の被災地へ派遣
- AIエージェントが車載アプリを動的に生成、イーソルがAIDVに向けた実験場を披露
- フィジカルAI時代のロボティクス新標準、安全性は「後付け」でなく「設計の核心」
- 富士通からC/C++およびJava対応のソースコード解析ツールの資産を取得
- MediaTek製SoCを搭載するSOMの事業を拡大、エッジAI開発の支援に向け
- “3つの頭脳”で80TOPSの処理性能を実現 AMDが語る「次世代AIチップ」戦略
- 上面放熱構造により高放熱と高耐圧を両立したSiC-MOSFETの新パッケージ
コーナーリンク



![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。