マルチコアで高速化処理を実現するための手法:組み込みマルチコア進化論(3)(2/3 ページ)
パイプライン並列化(同期タイミング検討)
並列化による高速化は、分割した処理をそれぞれのコアに割り当てて並列に処理することにより、高速化を図る手法です。しかし、実際には依存関係が存在する際の高速化は困難です。そこで有効な高速化手法がパイプライン並列化になります。
ここでいう依存関係とは、繰り返し処理内で使用している外部変数や内部変数を示しますが、依存関係がまったく存在しない場合には、コアの数だけ高速化が図れます。オーバーヘッドがあるので、実際にはそうはいきませんが、理論的には、コアが4つであれば、4倍の高速化が行えます。
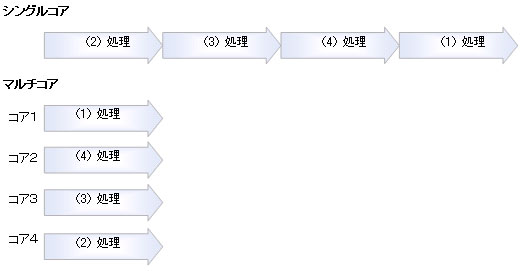 図3 依存関係がまったく存在しない場合の並列化処理(シングルコアとマルチコアの比較)
図3 依存関係がまったく存在しない場合の並列化処理(シングルコアとマルチコアの比較)しかしながら実際は、各コアの処理において依存関係が存在することが多く、その依存関係によって、性能が決定されます。例えば、図4の処理(1)で行った計算結果を処理(2)で使用する際などがそれに当たります。つまり、並列化は行われているものの、処理(2)は処理(1)の計算結果が動作するまで計算できない待ち状態になり、処理は実行されません。そのため性能アップが望めないという結果になります。
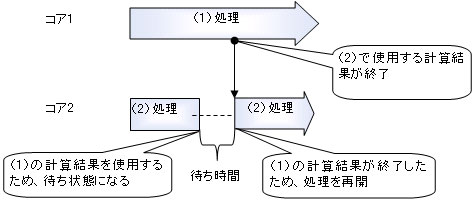 図4 依存関係がある場合のパイプライン並列化
図4 依存関係がある場合のパイプライン並列化そこで、タイミングを変更して並列処理を可能にするのが通常のパイプライン並列化です。パイプライン処理は、ハードウェア開発における高速化手法として使用されてきましたが、ソフトウェア開発にも有効な手法です。しかし依存関係が多い場合には処理が困難なばかりでなく、性能も低くなってしまうので、注意が必要です。
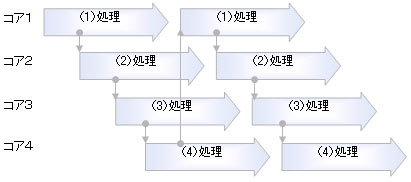 図5 依存関係を考慮したパイプライン並列化処理
図5 依存関係を考慮したパイプライン並列化処理「タスク並列化」については次回紹介する予定なので、今回は説明を省略します。
繰り返し処理における並列化の考え方
それでは、繰り返し処理における並列化の考え方ついて説明します。まず以下のサンプルコードを見てください。
ここで説明する処理はprintfのみですが、処理2が16回繰り返し実行されるプログラムです。
main1() {
int cnt;
printf( “処理1” ); //処理1
for( cnt = 0; cnt < 16; cnt++ ) {
printf( “処理2” ); //処理2
}
printf( “処理3”); //処理3
}
上記のソースコードを実行すると、図6のような流れで処理が行われます。最初に処理1が1回実行され、次に処理2が16回繰り返されます。そして、最後に処理3が1回実行されます。
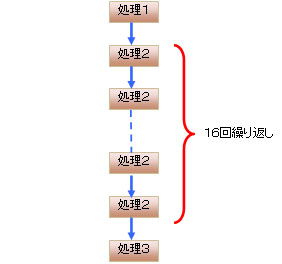 図6 繰り返し処理の実行例
図6 繰り返し処理の実行例次に分割検討を行います。図7の逐次処理では、処理2がcnt 0〜15の16回実行されます。その処理を4つに分割する場合「cnt 0〜3」「cnt 4〜7」「cnt 8〜11」「cnt 12〜15」に分割されます。では、それぞれを並列動作させることを検討してみましょう。
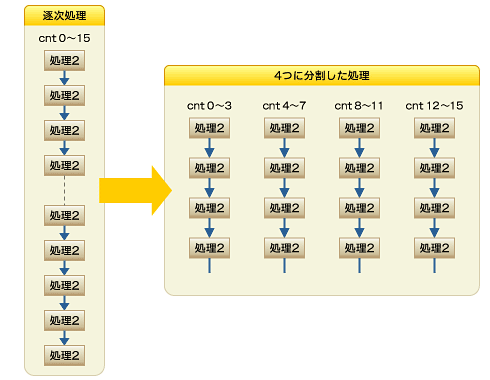 図7 分割検討において、処理を4つに分割した場合
図7 分割検討において、処理を4つに分割した場合スレッド割り当て
処理2を4つのコアに分割して動作させると、図8のようになります。
メインスレッドから処理1が動作された後、起動イベントが発行され、スレッド1でcnt 0〜3の処理、スレッド2でcnt 4〜7の処理、スレッド3でcnt 8〜11の処理、スレッド4でcnt 12〜15の処理が動作します。各スレッドは処理が終了した後、メインスレッドに終了イベントが発行され、メインスレッドではスレッド1〜4の処理が終了した後に、処理3が動作します。
スレッドの数としては、スレッド1〜スレッド4の4つとメインスレッドの合計5つのスレッドが存在することになります。
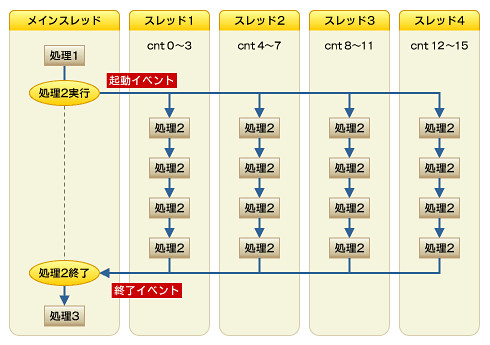 図8 処理2を4つのコアに分割した場合
図8 処理2を4つのコアに分割した場合処理実行時間の比較(効果)
逐次処理と並列処理の実行時間を比較すると、図9と図10の比較結果からも分かるように、並列処理の方が実行時間は短く、高速になります。
 図9 逐次処理をした際の実行結果
図9 逐次処理をした際の実行結果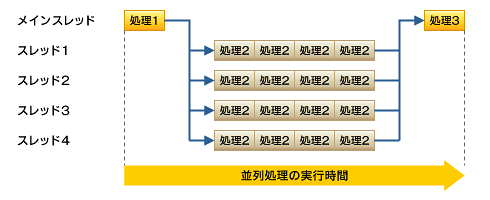 図10 並列処理をした際の実行結果
図10 並列処理をした際の実行結果Copyright © ITmedia, Inc. All Rights Reserved.
組み込み開発の記事ランキング
- “Hello, World”と「Lチカ」の共通点
- インフィニオンのヒューマノイド向け半導体戦略、2050年に3億台の市場を捉える
- サブ1nm半導体チップ技術を発表、性能最大50%向上
- Terra Drone、屋内点検用ドローン運用チームを熊本県の被災地へ派遣
- AIエージェントが車載アプリを動的に生成、イーソルがAIDVに向けた実験場を披露
- フィジカルAI時代のロボティクス新標準、安全性は「後付け」でなく「設計の核心」
- 富士通からC/C++およびJava対応のソースコード解析ツールの資産を取得
- MediaTek製SoCを搭載するSOMの事業を拡大、エッジAI開発の支援に向け
- “3つの頭脳”で80TOPSの処理性能を実現 AMDが語る「次世代AIチップ」戦略
- 上面放熱構造により高放熱と高耐圧を両立したSiC-MOSFETの新パッケージ
コーナーリンク



![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。