バグ検出ドリル(6)いろんなところにバグがいる! 2分探索法の問題:山浦恒央の“くみこみ”な話(106)(1/4 ページ)
「バグ検出ドリル」の第6回で出題するのは「2分探索法」の問題です。ソフトウェア技術者の誰もが心得ておくべき常識的なアルゴリズムである2分探索法ですが、今回の問題では、いろんなところにバグがあります。問題文から、どこにバグがありそうか見つけ出してみよう!
1.はじめに
ソフトウェアのバグは、さまざまな開発成果物に潜んでおり、バグがあると気付かずに使っていることも少なくありません。開発工程では大半のバグがリリース前までに見つかりますが、残ったものは市場へリリースした後もそのままとなります。タチの悪いものは、リリースしてから数年後に見つかるバグも少なくありません※1)。
本シリーズでは、エンジニアの品質意識向上を目的とし、皆さまにバグを見つけていただきます。今回の問題は、みんなが大好きな「2分探索法」の問題です。
 ※写真はイメージです
※写真はイメージです※1)私の弟が外科医をしており、「OSを含め『Word』や『Excel』などのソフトウェアは、10年以上前にリリースされた物を使う。最新版は絶対に使わない」と言っていました。最新版にアップグレードすると、患者のデータを入れたファイルが互換性の問題で読めなくなったりデータが化けたりする可能性があること、それ以上に、新しいソフトウェアはバグが枯れ切っていないので、怖くて使えないとのことでした。
20年以上前だと思いますが、マイクロソフトのカスタマーサポートセンターに胸部外科医から電話がかかり、「今、患者の心臓手術中なのだが、患者のExcelのデータを読めない。大至急、対策を教えてほしい」との緊急コールがあったそうです。また、1990年の湾岸戦争での「砂漠の嵐作戦」で、戦闘中の兵士から同サポートセンターに国際電話が入り、作戦遂行に必要なExcelのデータが読めないとのSOSが入ったとの話も聞いたことがあります。それまで、筆者は、航空管制システムや心臓のペースメーカーのソフトウェアに比べ、WordもExcelも、バグがあっても人の生死に関わらないので、開発者は品質制御から生じるストレスを受けないと思っていましたが、そうではないと知ってビックリ&反省しました。
2.逐次探索と2分探索法
問題を始める前に、2分探索法について復習します。2分探索法は、ソフトウェア技術者の誰もが心得ておくべき常識的なアルゴリズムですので、この機会に再学習してください(意外に、間違って覚えている場合があります)。
皆さんは、自分の読みたい書籍をどのような手順で見つけるでしょうか。例えば、全ての書籍が書名の「あいうえお順」で陳列している図書館で「やさしいコンピュータ」という本を探す場合を考えます※2)。一番簡単な方法は、最初の本から順々に探す「逐次探索」です(図1参照)。「あ」行の最初の本が「アインシュタインの自伝」から始まるものとすると、そこから右へ順々に探索します。書籍は名前の順でソートしてありますから、そのうち「や」行の欄にたどり着き「やさしいコンピュータ」が見つかりますね。
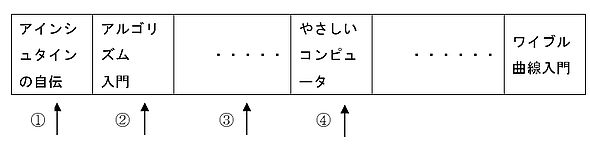 図1 逐次探索のイメージ
図1 逐次探索のイメージ※2)実際の図書館では、書名の「あいうえお順」ではなく、別の分類をしています。図書館に行くたびに素晴らしいと思うのは、「人間の内面、外面、地球上のものだけでなく、銀河系のあらゆるものの書籍、森羅万象の全てを分類している」ことです。図書館には、銀河系よりはるかに大きい宇宙があることになりますね。
日本の図書館で使っている分類法は「日本十進分類法」です。コンピュータやソフトウェアの情報処理系の本は、「新参者の学問」であるゆえ、007(情報科学)336(経営管理)418(数理統計)547(通信工学・電気通信)548(情報工学)とあちこちにばらまかれています。図書館で、書架を行ったり来たりして不便な思いをしたエンジニアが多いと思いますが、「日本十進分類法」の原形が誕生したのは1928年で、コンピュータの影も形もない時代。「現在の分類を維持しつつ、新しい学問を追加できる」分類法が理想ですが、残念ながら、「日本十進分類法」は、データベースでいう「階層型」を採用したため、上から下に向かって細かくなる木構造となり、「ハードウェア」「ソフトウェア」「通信」「離散数学」は別々の枝になってしまいました。今、考えると、図書の分類が、データ構造に依存しない「リレーショナル型」であればよかったとは思いますが、図書館情報学系の研究者は、使いやすい分類を目指して日夜、研究に励んでいます。
逐次探索は、非常に分かりやすく単純なアルゴリズムですが、無駄があります。例えば、最後尾の書籍を探す場合、わざわざ最初から探すと時間がかかります。
Copyright © ITmedia, Inc. All Rights Reserved.
組み込み開発の記事ランキング
- “Hello, World”と「Lチカ」の共通点
- インフィニオンのヒューマノイド向け半導体戦略、2050年に3億台の市場を捉える
- サブ1nm半導体チップ技術を発表、性能最大50%向上
- Terra Drone、屋内点検用ドローン運用チームを熊本県の被災地へ派遣
- AIエージェントが車載アプリを動的に生成、イーソルがAIDVに向けた実験場を披露
- フィジカルAI時代のロボティクス新標準、安全性は「後付け」でなく「設計の核心」
- 富士通からC/C++およびJava対応のソースコード解析ツールの資産を取得
- MediaTek製SoCを搭載するSOMの事業を拡大、エッジAI開発の支援に向け
- “3つの頭脳”で80TOPSの処理性能を実現 AMDが語る「次世代AIチップ」戦略
- 上面放熱構造により高放熱と高耐圧を両立したSiC-MOSFETの新パッケージ
コーナーリンク



![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。