映像を見て感じた内容を脳から言語化する脳情報デコーディング技術を開発:人工知能ニュース
NICT脳情報通信融合研究センターは、映像を見て感じた「物体・動作・印象」の内容を、脳活動を解読して1万語の「名詞・動詞・形容詞」の形で言語化する脳情報デコーディング技術の開発に成功した。
情報通信研究機構(NICT)は2017年11月1日、同機構脳情報通信融合研究センターの研究グループが、映像を見て感じるさまざまな「物体・動作・印象」の内容を、それらに対応する1万語の「名詞・動詞・形容詞」の形で言語化する脳情報デコーディング技術を開発したと発表した。
今回開発した技術では、大規模なテキストデータから学習した言語特徴空間を、脳活動を解読するデコーダーに取り入れ、映像を見て感じた内容の推定に利用する。ここでの言語特徴空間とは、単語同士の意味の近さや遠さを空間内の位置関係で表現する100次元空間のことで、テキストデータに含まれる1万語の「名詞・動詞・形容詞」がそれぞれ空間内の1点で表現され、意味の遠近が空間内の距離で表現される。
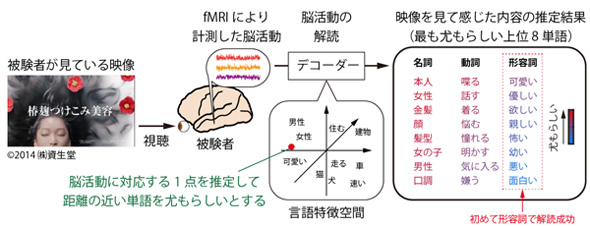 映像を見て感じた内容解読の1例 出典:情報通信研究機構
映像を見て感じた内容解読の1例 出典:情報通信研究機構この言語特徴空間を取り入れることで、従来技術の約20倍となる1万単語を用いた脳活動からの解読を可能にした。さらに、従来技術は名詞・動詞に対応する物体・動作の内容のみの解読だったが、言語特徴空間に含まれる形容詞を用いて、対応する「印象」内容も解読することに初めて成功した。
解読の対象となるのは、CMなどの自然な映像を視聴している被験者から機能的磁気共鳴画像法により計測した脳活動。解読を行うデコーダーは、脳活動と言語特徴空間の対応関係を保持しており、新しい脳活動が入力されると、対応関係により言語特徴空間内の1点を推定する。その点からの距離の近さに基づいて、1万の単語についてそれぞれ「もっともらしさ」を評価して名詞(物体)・動詞(動作)・形容詞(印象)に分けて出力し、映像を見て感じた内容を単語の形で推定する。
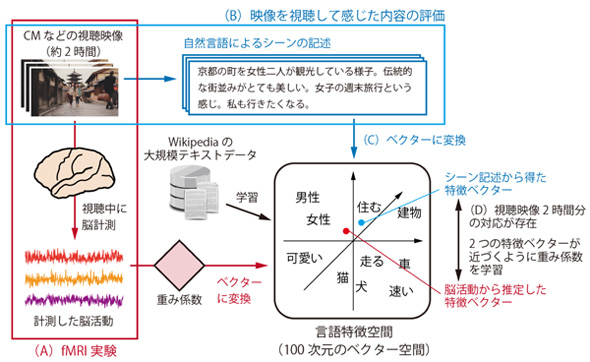 デコーダー構築の概要図 出典:情報通信研究機構
デコーダー構築の概要図 出典:情報通信研究機構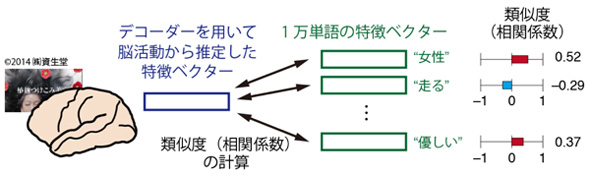 デコーダーの推定を用いた、映像を見て感じた内容を表すもっともらしい単語の推定 出典:情報通信研究機構
デコーダーの推定を用いた、映像を見て感じた内容を表すもっともらしい単語の推定 出典:情報通信研究機構脳情報デコーダーの構築に際しては、言語特徴空間の学習に、2013年にグーグル(Google)の研究者が開発した「word2vec」と呼ばれる技術を利用。また、脳活動と言語特徴空間の対応関係の推定には、それぞれのデータに機械学習を適用している。
同研究グループでは今後、映像から感じた内容の推定精度の向上を目指すとともに、推定された内容が個性や購買行動とどう結び付くのかについても検証を行う予定だ。また、発話や筆談が困難な人などが利用できる、発話を介しない言語化コミュニケーション技術についても産学官連携で社会実装を目指す。
なお同技術は、NICTからNTTデータにライセンス提供され、「脳情報デコーディング技術に基づいたCMなどの映像コンテンツ評価サービス」として、2016年度からNTTデータにより事業展開されている。
関連記事
 人がモノを見たり想像したりする時の脳活動を解読、人工知能への応用も
人がモノを見たり想像したりする時の脳活動を解読、人工知能への応用も
京都大学は、ヒトの脳活動パターンを人工知能モデルの信号に変換し、どんな物体を見たり想像したりしているかを脳から解読する技術を開発した。脳からビッグデータを利用する先進的技術となり、脳型人工知能の開発が期待できる。 AIに最適な脳型LSI、東北大が脳機能のモジュール化で2019年度に実現へ
AIに最適な脳型LSI、東北大が脳機能のモジュール化で2019年度に実現へ
東北大学の電気通信研究所は、2014〜2019年度のプロジェクトで、AI(人工知能)に最適な脳型LSIの開発を進めている。脳機能をモジュール化して計算効率を高め、人間の脳と同等レベルの処理能力と消費電力を持つ脳型LSIの実現につなげたい考えだ。 インテルはAIで勝ち残れるのか、脳科学研究から生まれた「Crest」に賭ける
インテルはAIで勝ち残れるのか、脳科学研究から生まれた「Crest」に賭ける
世界最大の半導体企業であるインテルだが、AIやディープラーニングに限ればその存在感は大きいとはいえない。同社は2017年3月にAI製品を開発するAIPGを発足させるなど、AI関連の取り組みを強化している。2017年3月に発足したAI製品事業部の副社長兼CTOを務めるアミール・コスロシャヒ氏に話を聞いた。 脳科学を活用してQOL向上へ、東北大学と日立ハイテクらが新会社を設立
脳科学を活用してQOL向上へ、東北大学と日立ハイテクらが新会社を設立
東北大学は、日立ハイテクノロジーズ、NSD、東北大学ベンチャーパートナーズ、七十七キャピタルと共同で、脳科学の産業応用事業を手掛ける新会社「株式会社NeU(ニュー)」を設立する。 なぜ小さな脳で巧みに探索行動できる? ハエに複数の情報を区別する並列神経回路
なぜ小さな脳で巧みに探索行動できる? ハエに複数の情報を区別する並列神経回路
理化学研究所は、ハエの脳信号を解読し、探索行動に関わる記憶/運動/視覚の異なる情報を区別して伝える並列神経回路を発見した。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
組み込み開発の記事ランキング
- “Hello, World”と「Lチカ」の共通点
- インフィニオンのヒューマノイド向け半導体戦略、2050年に3億台の市場を捉える
- サブ1nm半導体チップ技術を発表、性能最大50%向上
- Terra Drone、屋内点検用ドローン運用チームを熊本県の被災地へ派遣
- AIエージェントが車載アプリを動的に生成、イーソルがAIDVに向けた実験場を披露
- フィジカルAI時代のロボティクス新標準、安全性は「後付け」でなく「設計の核心」
- 富士通からC/C++およびJava対応のソースコード解析ツールの資産を取得
- MediaTek製SoCを搭載するSOMの事業を拡大、エッジAI開発の支援に向け
- “3つの頭脳”で80TOPSの処理性能を実現 AMDが語る「次世代AIチップ」戦略
- 上面放熱構造により高放熱と高耐圧を両立したSiC-MOSFETの新パッケージ
コーナーリンク



![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。