そのソフトウェア資産、ずっと使い続けられますか?:特集・現場で役立つリファクタリング(1/2 ページ)
長期間、改修を繰り返しながら、今なお現役で使い続けられているシステムはないだろうか。気が付けば設計担当者が去り、開発担当者が去り、ただ肥大化・複雑化・属人化したシステムだけが残され、運用担当者が何とかそれを維持し続けている。そんなシステムに対し、ある日、大幅な仕様変更・機能追加の命が下ったら……。
1.リファクタリングとは何か?
リファクタリングの登場
ソフトウェア開発の現場では、仕様変更や機能追加に対応できる“柔軟性”が求められることがあります。しかし、変更対象のソースコードが肥大化・複雑化・属人化していたら……。いざ、その対応が必要になったとき、ソフトウェア技術者にかかる労力的・精神的な負担は計りしれません。
そこで、日々の開発作業の中で“ソースコードを整理していく手法”が考え出されました。それが、本稿の主役「リファクタリング(refactoring)」です。

リファクタリングの定義と目的
リファクタリングの第一人者、マーチン・ファウラー(Martin Fowler)氏をご存じでしょうか。彼の著書『リファクタリング ― プログラムの体質改善テクニック』の中で、リファクタリングのことを
外部から見たときの振る舞いを保ちつつ、理解や修正が簡単になるように、ソフトウェアの内部構造を変化させること
と定義付けています。
例えば、ソースコードを理解しやすくするために「目的を正しく表す変数名に変更すること」や「式の結果や部分的な結果を、その目的を表す説明用変数に代入すること」などが該当します。
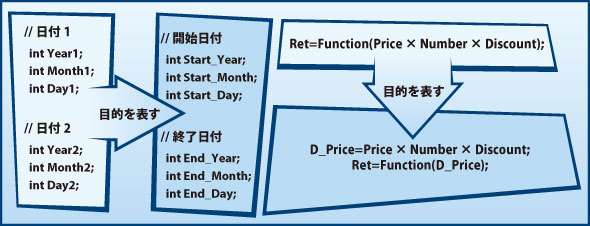
変数名を変更しても実行結果は変わらないので、「わざわざ変更する必要があるのか?」と疑問を感じるかもしれませんが、優れたソースコードは、自身の動作や目的を語っているものです。ソースコードを見ただけでその目的が分かるということは、ソフトウェア資産を活用し続ける上でとても大切なことなのです。
リファクタリング作業の1つ1つは小さな変更に過ぎません。しかし、その地道な積み重ねが、現在動作しているシステムに“将来のための価値”を与えていく作業になるのです。
処理の高速化・効率化を目的とするパフォーマンスの最適化と混同されがちですが、“ソースコードの理解度を向上させること”がリファクタリングの目的です。仮に、パフォーマンスの最適化が目的であっても、リファクタリングの後に最適化を行う方がはるかに効率的です。リファクタリングを実施することで、保守性・拡張性が向上し、それに伴って品質も高まります。
開発現場の実情
リファクタリングの重要性・有効性を認識しながらも、実際には実施できていないというケースが多いのではないでしょうか。以下に、開発現場でリファクタリングを躊躇(ちゅうちょ)してしまう主な理由を列挙します。
(1)ソースコードを変更することに対するリスクを払拭(ふっしょく)できない
プロジェクト管理者ならば「動いているソースコードに対し、下手に修正を加えたくない。万一、動かなくなったら困る」と考えるのは自然なことです。そのような考えの場合、リファクタリングを実施する範囲を限定して、小さな変更ごとに部分テストを実施するとよいでしょう。部分テストの着目点は、リファクタリング前後の対象コードの等価性です。外部から見たときの振る舞いを保つことが重要です。
(2)リファクタリングに必要なコストに見合う効果が得られるか明確でない
リファクタリングの有効性は知っていても、その効果を説明できなければ実施に踏み切れません。しかし、機能追加や不具合改修のためには、現在のソースコードを理解することから始めなければなりません。改修作業の前に、リファクタリングを実施することによって、ソースコードを早く、正しく理解できるようになり、全体の開発工程の短縮につなげることができます。さらに、複数の開発者が同一のソースコードを改修する場合にも有効ですし、1つの既存システムから複数の派生バージョンを作る場合にも大きな効力を発揮します。
(3)既に手を付けられないほどソースコードが複雑化している
流用開発を重ね、安易なコード複製や場当たり的な機能追加を繰り返してきたソフトウェアは、肥大化・複雑化・属人化していることが多く、リファクタリングに掛かるコストが増大する傾向にあります。このような場合、どうしたらよいでしょうか。以降で詳しく見ていきましょう。
2.複雑化したソースコードを再利用したい場合はどうするか?
では、手を付けられないほど複雑になってしまったソースコードを再利用したい場合は、どうすればよいのでしょうか? 以下、製造装置メーカーであるA社の事例を基に考察していきます。
製造装置メーカー(A社)の事例
ある製造装置メーカー(A社)では、次のような状況でした。
【現状】
- 10年以上プログラムを使い続けている
- ハードウェアが進化してもソフトウェアはプログラムの継ぎ足しで対処し、複雑化している
- 数十人の技術者が介入してきたが体制を維持できず、現状を把握できている者がいない
- 個別のエンドユーザー向けに、このプログラムを短期間でカスタマイズ対応している
- 類似コードや不要コードが多い
- 初回作成時のドキュメントしかなく、現ソースコードとドキュメントが一致していない
【悩み】
- 類似コードが多いため、機能を追加するときに改修箇所やテスト箇所が多い
- ドキュメントが更新されていないため、対応箇所の特定・分析にも時間がかかる
- ソースコードが複雑であるため、バグ改修時に必要な工数を正確に見積もることができず、計画通りに改修が完了しないことが多い
ハードウェアを独自で開発している製造業メーカーでは、既存ソフトウェアに手を加えながら新製品を開発する(ソフトウェアの寿命を引き延ばす)ことも多く、ソースコードは肥大化・複雑化する傾向にあります。また、ドキュメントの整備が行われておらず、システムが属人化してしまうと、保守できる技術者が限定されてしまうため、多くの場合、品質も劣化してしまいます。
特に、中小規模の製造装置メーカーなどでは、開発基準がなく、試作開発のソフトウェアがそのまま製品として出荷されるケースもあるため、出荷後の製品バグへの対応で多大な費用損失をしている場合が少なくありません。このようなレガシーシステムは数多く存在しているのです。
レガシーシステムに対する突破口・切り口
A社の場合、レガシーシステムに苦労している開発現場で、次の3つの手法を取り入れました。
(1)未使用コードの削除
・どこからも参照されていない関数およびそのプロトタイプ宣言、使用されないマクロ定義を削除する
・コンパイル対象外のソースファイル(どこからも参照されていない未使用ファイル)をソースコード一式から除外する
(2)類似コードの統合(一元化)
・類似した処理ブロックを、ある機能を持った関数として統合する
(3)静的解析による潜在バグの改修
・ソースコードの潜在的なバグを改修する
【潜在バグ例(C言語)】
- NULLポインタを参照する可能性を持つコード(プログラムが停止する可能性)
- 未初期化の変数を参照するコード(意図しない動作につながる可能性)
- 配列などの領域をはみ出してメモリを参照するコード(原因箇所を特定しにくいバグ)
- 実質的に無意味な処理(ロジックミスの可能性)
- 演算子の使用誤り(ロジックミスの可能性)
Copyright © ITmedia, Inc. All Rights Reserved.
組み込み開発の記事ランキング
- 日本再起の旗印となるか、国産マルチモーダルAI基盤「FRONTia」が始動
- サブ1nm半導体チップ技術を発表、性能最大50%向上
- TSMCの“Beyond 2nm”技術の現在地、「A14」で第2世代ナノシートトランジスタへ
- 大腸がんを低侵襲に治療できるESD、オリンパスが内視鏡ロボット技術で容易に
- 既設光ファイバーで450Tbps伝送に成功、周波数帯域幅を従来の4倍以上に拡大
- イチから全部作ってみよう(34)マルチプログラミングとトランザクション
- NVIDIAフアン氏が神田に現る――日本製造業巻き込む「ジャパンAI協業」祭り
- NVIDIAが「Jetson Thor」に新モジュール追加、高騰するメモリの使用量削減技術も
- インテグレーション地獄からの脱却:構造問題と「インテグレーター人権宣言」
- AIで脆弱性影響調査を自動化、管理工数を約70%削減
コーナーリンク



![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。