仮想ファイルシステムのありがたみを知ろう = ファイルシステム種別とスーパーブロックについて =:作りながら理解するファイルシステムの仕組み(7)(3/3 ページ)
補足情報:Linuxカーネルのリスト管理について
super_blockの双方向リストの実体は、「list_head」構造体です。list_headは、Linuxソースを読んでいると頻繁に出てくる構造体であるため、少し脱線して説明しておきます。
Linuxのような巨大なソフトウェアでは、非常に多種類のデータ型をリストで管理する必要があります。一方、データ型ごとにリスト管理データを作成するのは開発効率が非常に悪くなるため、型に依存しないリスト構造は必須となります。Linuxでは、このようなリスト構造として、以下に示すlist_head構造体を採用しています。
struct list_head {
struct list_head *next, *prev;
}
「next」と「prev」(注2)のデータの型は、list_headそのものになっており、特定のデータ型ではありませんよね。つまり、データ型に非依存となっているわけです。例えば、list_headを使って、以下の「tmpData」というデータ型を定義してみましょう。
struct tmpData {
int dataA;
int dataB;
struct list_head entry;
}
このデータ構造で、データがリストでつながっている様子を図8に示します。
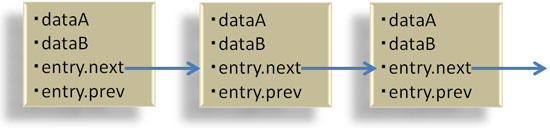 図8 list_headによるリスト管理
図8 list_headによるリスト管理nextのアドレスがtmpDataの先頭を指していないことに気付かれたでしょうか。仮に、リスト中のtmpDataを検索で見つけたとして、対象エントリのデータを参照・変更(dataAやdataB)する場合は、どうしたらよいでしょうか?
それをするには、先頭アドレスを導き出し、対象のデータ型でキャストする必要があります。この例の場合は、entryのアドレスから8バイト引いた値が先頭アドレスになります。しかし、この計算をデータ型ごとに行うのは手間なので、Linuxには「list_entry()」という便利なマクロが用意されています。その使い方をプログラムで書くと、例えば以下のようになります。
void setTmpDataA(struct list_head *list /* tmpDataのentryのアドレス */) {
struct tmpData *entry = list_entry(list, struct tmpData, entry);
//↑ listのアドレスを先頭にシフトし、型変換する
entry->dataA = 100; //dataAを変更する
}
super_blockを見てみよう
最後に、これまで説明してきたsuper_blockのデータ構造について、Androidエミュレータをデバッグして確認していきましょう。まず、super_blocksのリスト管理状況を見てみます(図9)。

super_blocksには、17個のsuper_blockがつながっていることが分かります(注3)。この中から、赤の点線で囲まれたsuper_blockの中のデータを見てみましょう(図10)。

super_blockの「s_type(file_system_type)」を参照することで、このファイルシステムの種別が分かります。file_system_typeの「name」メンバに“yaffs2”と書いてありますね。どうやらこのファイルシステムはyaffs2であるようです。それでは、yaffs2がAndroidエミュレータ上で何個マウントされているかを見てみましょう。fs_supersをたどっていくと、4個のsuper_blockがつながっていることが分かります。前回「AndroidエミュレータでLinuxカーネルをデバッグ!!」で、エミュレータ上でマウントしているファイルシステム一覧を表示しましたが、yaffs2のファイルシステムは確かに4個ありましたよね。
最後に、yaffs2が登録しているスーパーブロック操作関数(s_op)およびファイルシステム固有情報(s_fs_info)を見てみましょう(図11)。

s_opから、スーパーブロック操作関数テーブル(super_operations)を見ると、全部で18個の関数がありますが、yaffs2では6個しか登録していない(値としては0が設定されています)ことが分かります。このように登録されていない操作関数は、VFS層で判断され、デフォルトの処理が実行されるようになっています。なお、今回はyaffs2の操作関数を見ていますが、別のファイルシステムのsuper_blockでは、yaffs2とは異なる関数テーブルになります。
s_fs_infoには、「0xc5aff000」というアドレスが設定されています。ここに、yaffs2固有のスーパーブロック情報をポイントしているわけです。スーパーブロック操作関数とは違い、VFS層はこのデータに対するアクセスは行いません。yaffs2の固有の処理において、super_blockからs_fs_infoのアドレスを適宜キャストして使用することになります。
以上で、ファイルシステム種別、スーパーブロックについての主要なデータ構造を見てきました。これらのデータは、Linuxカーネルでファイルシステム全体を管理する重要なデータです。このデータを基点にして、inode情報やディレクトリ情報をたどることができるようになります。
次回は、普段何げなく見ているファイルがLinuxカーネル内でどのように管理されているのかを解説していきます。お楽しみに! (次回に続く)
関連記事
Copyright © ITmedia, Inc. All Rights Reserved.
組み込み開発の記事ランキング
- “Hello, World”と「Lチカ」の共通点
- インフィニオンのヒューマノイド向け半導体戦略、2050年に3億台の市場を捉える
- サブ1nm半導体チップ技術を発表、性能最大50%向上
- Terra Drone、屋内点検用ドローン運用チームを熊本県の被災地へ派遣
- AIエージェントが車載アプリを動的に生成、イーソルがAIDVに向けた実験場を披露
- フィジカルAI時代のロボティクス新標準、安全性は「後付け」でなく「設計の核心」
- 富士通からC/C++およびJava対応のソースコード解析ツールの資産を取得
- MediaTek製SoCを搭載するSOMの事業を拡大、エッジAI開発の支援に向け
- “3つの頭脳”で80TOPSの処理性能を実現 AMDが語る「次世代AIチップ」戦略
- 上面放熱構造により高放熱と高耐圧を両立したSiC-MOSFETの新パッケージ
コーナーリンク



![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。