ファイル名を管理するキャッシュdentry:作りながら理解するファイルシステムの仕組み(8)(1/2 ページ)
今回は、ファイル名、ディレクトリ階層構造、キャッシュの管理を担う「dentry」というデータ構造について詳しく解説する
前回「仮想ファイルシステムのありがたみを知ろう」では、仮想ファイルシステムがあるおかげで、“多種類のファイルシステムが共通インターフェイスを通して共存できる”ということを説明しました。
仮想ファイルシステムには、さまざまなデータ構造があります。今回はその中から、ファイル名を管理する「dentry」というデータ構造について解説していきます。
dentryとは?
dentryには、主に以下のような3つの役割があります。
- ファイル名の管理
- ディレクトリ階層構造の管理
- キャッシュ管理
これらの役割を担うために、dentryのデータ構造には表1に示すメンバが用意されています。
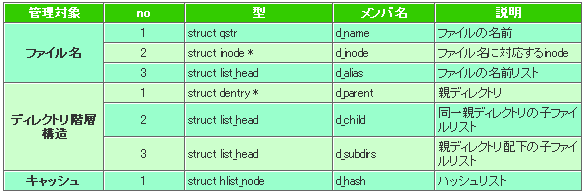 表1 dentryのデータ構造
表1 dentryのデータ構造前回説明しましたが、ここでも「list_head」構造体が出てきています。dentry構造体もリストだらけです。それでは、これらメンバの役割について少しつずつひもといていきましょう。
ファイル名の管理
はじめに、dentryのファイル名の管理を理解するために、以下のコマンドを実行してみましょう。
$ touch file_A ……(1)file_Aを作成する $ ln file_A file_B ……(2)file_Aのハードリンクfile_Bを作成する $ ls -i file_A file_B ……(3)file_A、file_Bのinode番号を表示する 10 file_A 10 file_B ……(4)file_A、file_Bのinode番号はともに10番
file_Aとfile_Bには、同じ「inode番号」が付いています。ハードリンクを実行すると、1つのファイルに複数の名前を付けることができます(注1)。この状態を図示すると、以下のようになります(図1)。
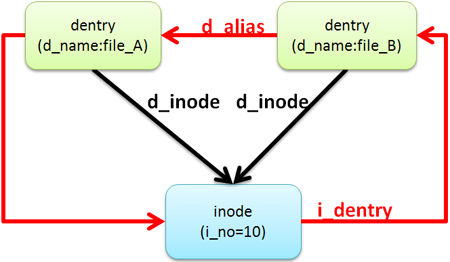 図1 ファイル名の管理
図1 ファイル名の管理まず、dentryの「d_name」には、ファイル名(file_A、file_B)が入っていることが分かります。同じinode(注2)を共有するdentry同士は「d_alias」で結び付いており、その先にあるinodeの「i_dentry」というメンバからdentryへと戻っていく構造になっています。各dentryからは、「d_inode」というメンバで直接inodeをポイントすることで、inodeを直接参照できるようにしています。
ディレクトリ階層構造
dentryは、ディレクトリ階層構造も管理できます。
以下、「testDir」配下に2つのファイル(article_1、article_2)が存在している状態のdentryのディレクトリ階層管理を見てみましょう(図2)。
- testDir
- testDir/article_1
- testDir/article_2
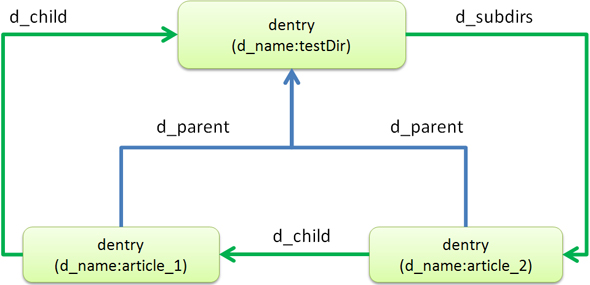 図2 ディレクトリ階層構造
図2 ディレクトリ階層構造まず、testDirという名前を持つdentryが頂上におり、その「d_subdirs」というメンバから、子ファイルであるarticle_2、article_1へとたどることができます。この際、子ファイル同士は「d_child」というメンバでアクセスすることになります。そして、子ファイルのdentryの「d_parent」というメンバには親ディレクトリのdentryがポイントされており、直接親ディレクトリへアクセスできるようになっています。
キャッシュ管理
dentryには、“キャッシュ”という重要な役割があります。dentryがキャッシュ管理されているおかげで、非常に高速にファイルのアクセスが可能となります。実例として、x86 Android仮想マシン上でファイルアクセスの高速化度合いを測ってみました。
テスト環境
テスト内容
Androidの全ファイルのリストアップを2回行い、1回目と2回目のファイルアクセス性能を測定しました。具体的な実行コマンドは以下のとおりです。
# time -p ls -R / > /dev/null # time -p ls -R / > /dev/null
dentryキャッシュ効果の確認方法
dentryのキャッシュ数は、「/proc/slabinfo」のdentryの行をチェックします。具体的な実行コマンドは以下のとおりです。
# cat /proc/slabinfo | grep dentry
テスト実行結果
 表2 テスト実行結果
表2 テスト実行結果驚くべきことに、実行時間は200倍以上も向上しました。この要因がキャッシュ効果であることは、コマンド実行前のdentryキャッシュ数を見れば分かります。ご覧のとおり、dentry数は13倍以上も増加していますよね。キャッシュがあることで、CPUのアクセスはメモリ(dentry)だけで済み、時間のかかるUSBメモリへのアクセスはスキップされるのです。これこそがキャッシュ効果の威力です!
dentryのキャッシュ管理ですが、図3のようにハッシュ管理されています。
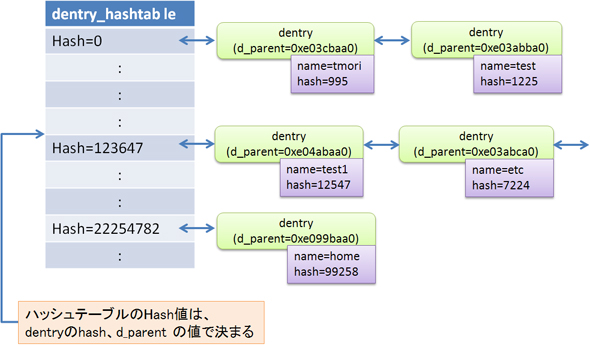 図3 dentryのハッシュリスト
図3 dentryのハッシュリストまず、図3のdentryの右下にある紫色の「name」と「hash」は、「qstr」構造体の実体です。ここにファイルの名前とハッシュ値が入ります。このハッシュ値は、ファイルの名前から計算で求められるもので、32ビットの変数です。ファイル名検索の処理の論理だけを考えるのであれば、“dentryごと”にハッシュ値は必要ありません。単に、検索したいファイルの名前とdentryのファイルの名前を比較すればよいだけです。
しかし、これだと大量にファイルが存在する場合、この文字列比較処理が性能ネックになり得ます。文字列比較のロジックは、1文字ずつチェックを掛けて、最大でファイル名長分だけチェックが入ります。例えば、ファイル総数が10万個で、平均ファイル名長が10文字である場合、最大で100万回(=10万×10回)のチェックが入ることになります。一方、ファイル名の一致性のチェックがハッシュ値だけで済むのであれば、1dentry当たりのチェックは1回だけで終わるというわけです。
すべてのdentryは、ハッシュテーブル内のどこかのエントリに登録されています。対象となるエントリは、dentryのd_parentのアドレス値とファイル名で求めたハッシュ値(図3中のHash)で求められます。すなわち、対象となるエントリは、ハッシュテーブルの先頭からハッシュ値番目のエントリが使用されます。
Copyright © ITmedia, Inc. All Rights Reserved.
組み込み開発の記事ランキング
- TSMCの“Beyond 2nm”技術の現在地、「A14」で第2世代ナノシートトランジスタへ
- 大腸がんを低侵襲に治療できるESD、オリンパスが内視鏡ロボット技術で容易に
- 日本再起の旗印となるか、国産マルチモーダルAI基盤「FRONTia」が始動
- 製造業の設計開発と情シスの部門間にある「ダニング・クルーガー効果」の谷
- 既設光ファイバーで450Tbps伝送に成功、周波数帯域幅を従来の4倍以上に拡大
- 酸素供給スーツで3時間潜水するサイボーグ昆虫
- NVIDIAが「Jetson Thor」に新モジュール追加、高騰するメモリの使用量削減技術も
- インテグレーション地獄からの脱却:構造問題と「インテグレーター人権宣言」
- 先端パッケージ技術の採用加速へ、図研がTSMCのEDAアライアンスに参加
- AIエージェントを作って終わりから「自己進化」へ、富士通MAAF検証開始
コーナーリンク



![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。