
機械学習とディープラーニング、どちらを使えばいいのか:AI基礎解説(1/2 ページ)
研究開発プロジェクトを先に進めるためにどのようなAI技術を使用すればいいのだろうか。本稿では、その一助とすべく、機械学習とディープラーニング(深層学習)の違いについて概説し、それぞれをどのように適用すべきかについて説明する。
科学技術の急速な成長と進化のおかげもありますが、研究開発プロジェクトを先に進めるためにどのようなAI(人工知能)技術を使用するかを理解し、定めることは困難です。本稿では、その一助とすべく、機械学習とディープラーニング(深層学習)の違いについて概説し、それぞれをどのように適用すべきかについて説明します。
定義:機械学習vs.ディープラーニング
機械学習とディープラーニングの両方において、エンジニアはMATLABなどのソフトウェアツールを使用して、コンピュータがサンプルデータセットから学習することで、データの傾向や特性を識別できるようにします。
まず機械学習の場合、学習データを使用して、コンピュータがテストデータや、最終的には実世界のデータを分類するために使用できるモデルを構築します。従来、このワークフローの重要なステップは、モデルの精度を高める特徴量(生データから抽出した追加メトリクス)の開発になります。
一方のディープラーニングは機械学習の一部ですが、エンジニアや科学者は機械学習のように特徴量を手動で作成する手順をスキップできます。代わりに、データはディープラーニングアルゴリズムに入力され、出力を決定するために最も有用な特徴量を自動的に学習します。
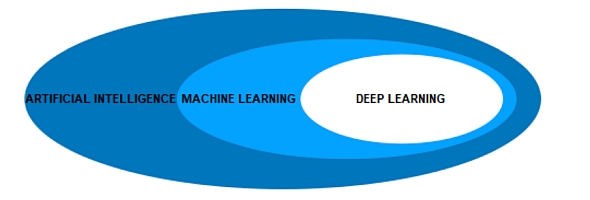 AI技術の中に機械学習があり、機械学習の1種としてディープラーニングがある(クリックで拡大)
AI技術の中に機械学習があり、機械学習の1種としてディープラーニングがある(クリックで拡大)以下に、機械学習とディープラーニングの定義についてまとめておきましょう。
- 機械学習:エンジニアや科学者がデータ内の特徴量を手動で選択し、モデルを学習させるAIの一種
- ディープラーニング:人間の脳の神経経路を大まかにモデル化したもので、機械学習の一種。アルゴリズムが自動的に有用な特徴量を学習する
適しているプロジェクト
機械学習は、通常、出力の予測や傾向の発見を伴うプロジェクトに使用されます。これらの例では、限られたデータを使用して、新しい入力データを正しく判断するために後で使用できるパターンを学習器が学習します。機械学習で使用される一般的なアルゴリズムには、線形回帰、決定木、サポートベクターマシン(SVM)、単純ベイズ、判別分析、ニューラルネットワーク、アンサンブル法などがあります。
ディープラーニングはより複雑で、通常は画像の分類、画像内のオブジェクトの識別、画像や信号の増幅を伴うプロジェクトに使用されます。このような場合、画像や信号などの空間的および時間的に構成されたデータから特徴を自動的に抽出するように設計されている、ディープニューラルネットワークが適用可能です。ディープラーニングで使用される一般的なアルゴリズムには、畳み込みニューラルネットワーク(CNN)、再帰型ニューラルネットワーク(RNN)、強化学習(DQN、Deep Q-Network)などがあります。
より早く結果が必要な場合は、機械学習の方が望ましいことがあります。学習スピードが速く、計算能力も少なくて済みます。特徴量と観測値の数は、学習時間に影響を与える重要な要因になります。機械学習を適用するエンジニアは、モデルの精度を向上させるために、特徴量の開発と評価に多くの時間を費やすことを考慮する必要があります。
ディープラーニングモデルは、学習に時間がかかります。学習済みネットワークとパブリックデータセットを使用すると、転移学習により学習時間が短縮されますが、実装が複雑になる場合があります。一般に、ディープラーニングアルゴリズムの学習は、ハードウェアと計算能力に応じて、1分で済む場合もあれば数週間かかる場合もあります。ディープラーニングを適用するエンジニアは、モデルの学習や、ディープニューラルネットワークのアーキテクチャに変更を加えることに多くの時間を費やすことを考慮する必要があります。
Copyright © ITmedia, Inc. All Rights Reserved.
組み込み開発の記事ランキング
- “Hello, World”と「Lチカ」の共通点
- インフィニオンのヒューマノイド向け半導体戦略、2050年に3億台の市場を捉える
- サブ1nm半導体チップ技術を発表、性能最大50%向上
- Terra Drone、屋内点検用ドローン運用チームを熊本県の被災地へ派遣
- AIエージェントが車載アプリを動的に生成、イーソルがAIDVに向けた実験場を披露
- フィジカルAI時代のロボティクス新標準、安全性は「後付け」でなく「設計の核心」
- 富士通からC/C++およびJava対応のソースコード解析ツールの資産を取得
- MediaTek製SoCを搭載するSOMの事業を拡大、エッジAI開発の支援に向け
- “3つの頭脳”で80TOPSの処理性能を実現 AMDが語る「次世代AIチップ」戦略
- 上面放熱構造により高放熱と高耐圧を両立したSiC-MOSFETの新パッケージ
コーナーリンク



![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。