tarファイルに魔法をかけてみよう! その1 = tarfsのデータ構造 =:作りながら理解するファイルシステムの仕組み(4)(2/2 ページ)
間接エクステント管理データ
ファイルデータの配置場所の管理は、inodeのメンバであるエクステントで行います。ただし、表1のエクステントを見てみると、最大で17個しか登録できないことが分かります。
通常ファイルの場合、ユーザーデータはtarファイル内に存在する連続した領域にあり、エクステントは1個しか消費しないため問題はありません(注3)。また、シンボリックリンクの場合、リンク先パス名のデータはエクステントを使用せずに、tarファイル内にあるリンク先パス名を参照するため問題はありません。しかし、ディレクトリの場合、ディレクトリデータはtarファイル内に存在しないため、新たに作成していく必要があり、エクステントの総数が17個以内に収まる保証はありません。
よって、18個目以降のエクステントを管理するために、エクステントだけを管理する特別なメタデータとして、間接エクステント管理データを使います(表4)。
| 間接エクステント管理データ情報 | メンバのデータサイズ(bytes) | 意味 | |
|---|---|---|---|
| マジック番号 | 8 | 間接エクステント管理データのマジック番号 | |
| 次の間接エクステント 管理データのブロック番号 |
8 | 間接エクステント管理データを線形リスト(単方向)で管理するためのメンバ | |
| エクステント数 | 4 | この間接エクステント管理データに登録されているエクステントの総数 | |
| パディング | 12 | 未使用領域 | |
| エクステント情報[20] | 480(20*24) | この間接エクステント管理データに登録されているエクステント。最大で20個のエクステントが登録される | |
| 表4 間接エクステント管理データ情報 | |||
この間接エクステント管理データに収納できるエクステント数は20個であるため、さらにエクステント領域が必要な場合は、間接エクステント管理データを増やしていきます。このとき、複数の間接エクステント管理データは、図5のように線形リストで管理されます。
 図5 間接エクステントデータのリスト管理
図5 間接エクステントデータのリスト管理一般的に、ディレクトリ配下に大量のファイルが存在する場合は、エクステント数が増えていきます。このため、図6に示すようなデータ構造になります。
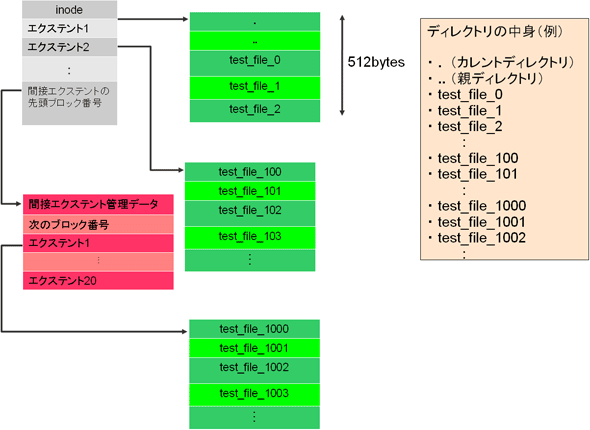 図6 大量のファイルを管理するディレクトリデータのイメージ図
図6 大量のファイルを管理するディレクトリデータのイメージ図これで、tarfsの基本となるメタデータについての説明が一通り終わりました。ここまでの解説で、tarfsのinodeを起点にして、ディレクトリデータ、ユーザーデータ、シンボリックリンクパス名を参照する方法を理解できたと思います。
では、inodeについては、どうやって参照すればよいでしょうか? 例えば、ディレクトリデータ内で検索対象となるファイル名を見つけ、そのファイル名に対応するinode番号が分かったとしても、そのinodeがどこに存在するのか分からなければ意味がありません。
inode管理領域がひとまとまりになっていれば、連載第2回のinode領域の説明のとおり、inode番号から対象個所を特定することも可能ですが、tarfsの個々のメタデータ領域は、散らばった構造になっているため、単純には特定できません。
そこで、inodeの配置状況を管理する「特殊inode(ino=0)」というものを導入することにしました。恐らく、そういわれてもピンとこないと思いますので、もう少し具体的に説明していきます。
まず、tarfsのinodeデータ領域ですが、複数のエクステントで表現できます。
例えば、図7のように、3つのinode領域が存在しているとします。
この場合、3つのエクステントが存在していることになり、「論理オフセット=inode番号」ととらえると、エクステントは表5のように表現できます。
| エクステント | inode番号 | 物理オフセット | サイズ | |
|---|---|---|---|---|
| エクステント1 | 0 | 1 | 3 | |
| エクステント2 | 3 | 5 | 2 | |
| エクステント3 | 5 | 8 | 2 | |
| 表5 図7のinode領域のエクステント表現 | ||||
inode番号が「4」のinodeを検索するには、このエクステントのinode番号とサイズから、エクステント2が対象のinodeを管理していることが分かり、その物理オフセット位置は「6」であることを特定できます。
これで、エクステント情報から対象のinodeを特定するための仕組みが理解できたと思います。後は、このエクステントを誰が管理するのか? という問題だけです。
これまでの説明で、“エクステントの管理はinodeが行っている”ということを理解できたと思います。そうです。inodeがこのエクステントを管理するのが一番自然なのです。そこで、inode領域を管理する特殊inodeを作ったというわけです。後は、この特殊inodeの配置場所をスーパーブロックが知っていれば、スーパーブロックを起点にして、すべてのメタデータにアクセスすることができます。
図8に、そのイメージを示します。
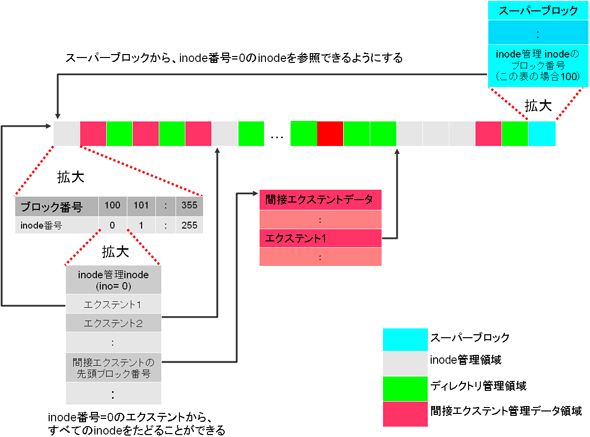 図8 特殊inodeによるinode管理イメージ図
図8 特殊inodeによるinode管理イメージ図以上、tarfsのデータ構造についての説明が一通り終わりました。
ここで紹介したデータ構造は、ほんの一例であり、“これが正解”というものではありません。改良する余地はまだまだあると思います。「腕試しをしたい!」という読者の方は、以下のサイトからソースをダウンロードして、自分専用のtarファイルシステムを作ってみてはいかがでしょうか。より理解が深まると思いますよ。
さて、次回は「ファイルシステムとしてマウントするまでの処理の流れ」をテーマに、tarfsのメタデータを実際に作るコマンドと、tarファイルをマウントする仕組みについて解説します。ご期待ください!(次回に続く)
関連記事
Copyright © ITmedia, Inc. All Rights Reserved.
組み込み開発の記事ランキング
- “Hello, World”と「Lチカ」の共通点
- インフィニオンのヒューマノイド向け半導体戦略、2050年に3億台の市場を捉える
- サブ1nm半導体チップ技術を発表、性能最大50%向上
- Terra Drone、屋内点検用ドローン運用チームを熊本県の被災地へ派遣
- AIエージェントが車載アプリを動的に生成、イーソルがAIDVに向けた実験場を披露
- フィジカルAI時代のロボティクス新標準、安全性は「後付け」でなく「設計の核心」
- 富士通からC/C++およびJava対応のソースコード解析ツールの資産を取得
- MediaTek製SoCを搭載するSOMの事業を拡大、エッジAI開発の支援に向け
- “3つの頭脳”で80TOPSの処理性能を実現 AMDが語る「次世代AIチップ」戦略
- 上面放熱構造により高放熱と高耐圧を両立したSiC-MOSFETの新パッケージ
コーナーリンク



![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。