ベンチマーク結果に注目せよ!
GPGPUに最適な解析環境を明らかに:あの汎用FEM解析ツールがGPGPUに対応
サイバネットシステムが提供する「ANSYS Mechanical」のRelease 13.0では、かねてからユーザーの注目が高かったGPGPU(ジーピージーピーユー)に対応! どんどん大規模化する構造解析がより快適に、詳細になる。同社と富士通共同のベンチマークデータを検証して、より快適な構造解析環境を手に入れよう。
サイバネットシステムが提供する汎用FEM(有限要素法)解析ツール「ANSYS Mechanical」。Release 13.0では、兼ねてからユーザーからの注目が高かったGPGPUに、構造解析機能が対応した。
近年、アセンブリモデルを丸ごと解析したり、より詳細な解析を行いたいといったニーズにより、解析規模は増大の一途をたどっている。GPGPUのような最先端のハードウェアを活用することで、そうした大規模問題を効率よく解くことが可能になるが、GPGPUとPCクラスタのどちらが効果的なのか、頭を悩ます方も多いことだろう。
ここでは、同社と富士通が共同で作成したベンチマーク結果を紹介する。しっかり検証して、自社に最適な大規模解析の環境を手に入れよう。
ANSYS MechanicalをはじめとしたANSYSシリーズ製品の歴史は古く、初代バージョンのリリースは1970年代にまでさかのぼる。以後、バージョンアップの度に機能強化が進み、2010年10月にリリースされた最新バージョンでは、以下の3点が追求されている。
- 解析精度のさらなる向上
- 解析作業の一層の効率化
- パフォーマンスの向上
解析精度の向上に関しては、構造解析における新しい連成場要素の搭載や各種メッシング技術の拡張などが挙げられる。作業の効率化については、統合操作環境である「ANSYS Workbench」におけるExcelとのリンクや、非線形解析におけるリスタート機能、また低周波磁場解析ツール「Maxwell」と「Mechanical」による片方向連成解析がANSYS Workbench上できるようになった。
そして中でも注目したいのが、3つ目のパフォーマンスの向上だ。ANSYS MechanicalではRelease 13.0で、汎用構造解析アプリケーションにおいて初めてGPGPU(General Purpose Graphical Processing Unit)に対応した。
GPGPU対応は技術者にとって福音か!?
米国ANSYS, Inc.はパラレルコンピューティングによる大規模モデルへの対応を精力的に進めてきており、今回もいち早く最新の流れに対応した格好だ。
「以前より、GPGPUに対するユーザー様の注目度は大きく、Release 13.0のリリース前からGPGPUの対応について問い合わせを受けていました」(サイバネットシステム メカニカルCAE事業部 MC第2ビジネスユニット 技術グループ 宗像佳克氏)。

 (左)サイバネットシステム メカニカルCAE事業部 MC第1ビジネスユニット 技術グループ 宮内隆太郎氏
(左)サイバネットシステム メカニカルCAE事業部 MC第1ビジネスユニット 技術グループ 宮内隆太郎氏従来、GPGPUの事例としては、研究所や企業で独自のインハウスプログラムによって安価なGPGPUで高速化しているということがほとんどだった。「そういった環境の中で、汎用のソフトウェアとして初めてGPGPUに対応した点が評価されているようです」(宗像氏)。
GPGPUに対する現場の捉え方はさまざまである。「比較的安価に、CPUの並列化と同等あるいはそれ以上の効果が得られるのではないか」という期待がある一方で、「本当に効果が出るものなのか」といった不安の声もある。
そうした中、GPGPUが汎用FEMソフトウェアに対してどれほど効果が見込めるのか、サイバネットシステムでは以前から技術的な検証を積み重ねてきた。今回のRelease 13.0では、ANSYS, Inc.がベンチマーク用に提供している標準モデルを基に、富士通と共同でベンチマークを実施している。
その一例が図1だ。解析環境を変化させて解析のスピードを調べたものである。
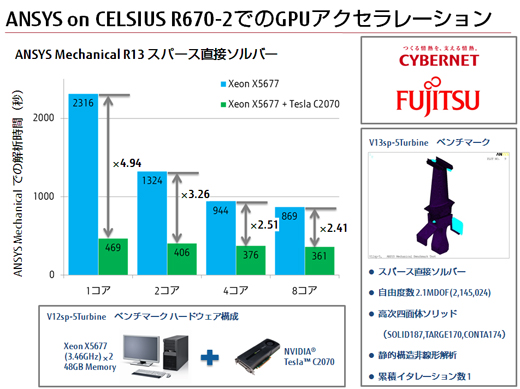 図1 青はCPUによるDMP(分散メモリ並列)による解析時間、緑はGPGPUによるSMP(共有メモリ並列)による解析時間
図1 青はCPUによるDMP(分散メモリ並列)による解析時間、緑はGPGPUによるSMP(共有メモリ並列)による解析時間図1はGPGPUを使用しない場合と使用した場合の解析時間をグラフで表したものだ。富士通のワークステーション「CELSIUS(セルシアス) R670-2」を使用し、CPUはIntel社製の「Xeon X5677」×2個(8コア)である。グラフィックスカードはNVIDIA製の「Tesla C2070」を使用している。青がグラフィックスカードを使わず、緑がグラフィックスカードを使って解析した場合だ。青はDMP(Distributed Memory Parallel:分散メモリ並列)、つまりPCクラスタでも使える。緑がグラフィックスカードを使用したSMP(Shared Memory Parallel:共有メモリ並列計算)で、こちらは1台のPCで処理を行う。コア数によって性能比が異なることが分かる。
*ANSYS Mechanicalについて、GPGPUはDMP未対応
GPGPUで効果的な解析モデルが明らかに
サイバネットシステムと富士通がさまざまなベンチマークを行った結果、GPGPUが適切な規模やモデルなどの情報が蓄積できつつあるという。「私たちは“スイートスポット”と呼んでいますが、GPGPUに適したモデル規模が存在することが、今回の富士通様との共同検証の結果、分かってきました」(サイバネットシステム メカニカルCAE事業部 MC第1ビジネスユニット 技術グループ 宮内隆太郎氏)。
それがはっきりと確認できるのが、解析事例と性能についてマッピングした図2だ。

図2の性能測定条件
[測定環境]
Fujitsu CELSIUS R670-2 Workstation×1Unit,
Xeon 5677(3.46GHz, 4 Core)×2 Socket, DDR3 1333 RDIMM×12(48GB),
Hyper Thread OFF, Turbo Boost OFF,
NVIDIA Tesla C2070 Computing Processor(6GB MEM), ECC On,
Windows 7 Professional, Microsoft MPI, ANSYS Mechanical 13.0SP2
| 測定内容 | 使用リソース | 備考 | |
|---|---|---|---|
| GPU | CPU | ||
| SMP (Shared Memory Parallel) |
- |
1,2,4,8コア | スレッド並列処理を CPUのみで実行 |
| DMP (Distributed Memory Parallel) |
- |
1,2,4,8コア | プロセス並列処理を CPUのみで実行 |
| GPU | ○ |
1,2,4,8コア | スレッド並列処理を CPU+1GPUで実行 |
横軸に表示されているのは個々のベンチマークモデルの詳細である。縦軸は、それぞれのモデルにおける性能、つまり1コアで計算した場合の計算スピードと、複数コアの場合の性能比を示している。
なおここでは、直接法であるSPARSEソルバーを利用している。これはANSYSの多種多様なソルバーの1つであり、静的解析および過渡解析に適用でき、不安定行列問題に有効である。
このグラフから、SPARSEソルバーでは自由度数(以降DOF)が200万以上、500万以下のモデルにGPGPUが有効であることが分かる。
現場に近いモデルを多数紹介
「最近は単体のパーツで解析するケースは減っているようです。3次元アセンブリをそのまま持ってきて、設計者自身が解析を行うということも増えています」(宮内氏)。
その例が図2の左から1番目のユニバーサルジョイントだ。3次元CADで作成したアセンブリモデルをANSYS Workbenchで読み込んだもので、複数の部品同士の接触がある。解析規模が小さいため(43万DOF)GPGPU使用によるメリットは現れていないが、さらに大きくなると効果が出るケースだ。
同様に図2の左から2番目はペルチェ素子のモデルであり、熱と電気の連成解析、3番目はシェル構造、4番目は固まりの一体物、一番右はタービンブレードの一部だ。ほかにも過渡解析などさまざまな条件での例を用意している。「ユーザーが行っている解析について、最大公約数的なものをANSYS, Inc.が選定し、ベンチマークのリストとして挙げました。パフォーマンスの出方の参考にしてもらえれば」(宗像氏)。
以上のデータを見ても分かるように、SPARSEソルバーの場合は非線形で、解析規模が大きなときに効果を発揮することが分かる。GPGPUを使って大きな効果を出せるモデルと、あまり変わらないモデルとがあることに注目したい。
PCクラスタとGPGPUの使い分け
連成問題やマルチフィジクスといった複雑な解析を行う場合、より速い並列計算を望むなら、GPGPUよりもPCクラスタが適している。連成に限らず構造非線形モデルでも、PCクラスタを導入するメリットがある。
「構造非線形モデルについてもPCクラスタの使用は増えています。いままでワークステーションを使っていたが、最近はソルバーのジョブをネットワーク経由でPCクラスタに投げ、手軽に結果を得るといった使い方をしているユーザー様もおられるようです」(宗像氏)。
これは、ネットワークの高速化や画像圧縮技術の進歩などがポイントだと宗像氏は言う。「CAEは、解析結果を評価しながら設計変更を繰り返していくことで、そのメリットが最大限に発揮されます。昔は各システムが成熟しておらず現実的ではありませんでしたが、現在は通信技術をはじめ各技術が進歩してきたため、大規模なモデルでもそのような活用がしやすくなってきました」(宗像氏)。
PCクラスタのメリットは何と言っても「大規模」であることに尽きるということだ。GPGPUで計算する際のSMPではメモリを積む量に限界がある。「構造や流体、磁場などをマルチフィジクスで捉えようとすると、解析モデルの規模も指数関数的に大きくなります。従って大規模なメモリを潤沢に使わないと計算時間がかかってしまいます。そこでPCクラスタの出番となります」(宮内氏)。またコア数と必要なメモリとのバランスを考えることも必要だ。その点、PCクラスタであれば柔軟に対応できるのも大きな特長である。
PCクラスタやGPGPUなど選択肢が増えることによって、解析分野や規模に応じたより適切な環境が選べる。ユーザーにとってはますます便利になりそうだ。自分の扱う解析はGPGPUに適しているのか? 豊富な解析事例シミュレーションデータを持つサイバネットシステムのサポートに相談してみるのもいいだろう。
PCクラスタは、環境配慮面でも有利
PCクラスタのメリットが計算の高速化であるのはもちろんだが、ワークステーションサーバを集約した場合の省電力や省スペースというメリットも見逃せない。タワー型のサーバやワークステーションの複数連結は設置スペースがかさばるが、例えばブレードサーバに集約すれば、設置スペースを約83%、消費電力を約11%削減できる場合もある。
◇
サイバネットシステムが提供する新版のANSYS Mechanicalでは、GPGPU対応という1つの大きなステージを迎えた。一層進化する解析機能を活用して、さらなる充実したモノづくり環境を構築してほしい。


Copyright © ITmedia, Inc. All Rights Reserved.
提供:富士通株式会社
アイティメディア営業企画/制作:@IT MONOist 編集部/掲載内容有効期限:2011年10月31日
提供

読者アンケート

関連記事
- まずは既存システムの仮想化統合で開発力を強化
- 今こそ求められる燃費効率化&設計効率化
- アドオンするだけで解析業務効率が大幅にアップ
- ベンチマーク結果に注目せよ!GPGPUに最適な解析環境を明らかに
- 高効率世界一を目指せ!〜会社を元気にする解析環境構築〜
- 富士通、8ポートInfiniBandスイッチ採用で小規模PCクラスタを廉価に
- 富士通がPCクラスタ導入をサポートする設備を開設
- モノづくリストの道標! 解析業務アラカルト
- 深遠なる流体解析の世界に挑むハイエンドツール! “真の”使いこなしへの道
- もっと高度な構造解析がやりたい! しかし時間も大幅短縮したい!
- It's a Real World! ――バーチャル実験室が変える製品開発の未来
- MD(複合領域解析)は単なる連成解析ではない――中堅企業も要注目な新・解析環境
- 自分が知りたいことだけ検証できる
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。