深層学習研究用のプライベートスパコンが稼働開始、民間では国内最大規模:人工知能ニュース
Preferred Networksは、深層学習を研究開発するためのプライベートスーパーコンピュータの稼働を開始した。計算ノードにNVIDIA製のTesla P100 GPUを1024基搭載し、民間企業の計算環境としては、国内最大規模のスーパーコンピュータとなる。
Preferred Networks(PFN)は2017年9月20日、深層学習(ディープラーニング)を研究開発するためのプライベートスーパーコンピュータを、同年9月から稼働したと発表した。
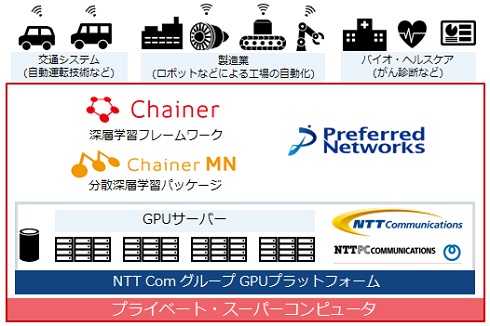
同スーパーコンピュータに採用したのは、NTTコミュニケーションズ(NTT Com)およびNTTPCコミュニケーションズの高速演算処理(GPU)プラットフォームだ。同プラットフォームには、NTT comグループのGPUサーバにおける技術力と実績、最先端のデータセンター構築のノウハウが生かされている。PFNは同プラットフォーム上に、独自の並列分散学習技術「ChainerMN」を活用するための、大規模な深層学習用研究開発基盤を構築した。
計算ノードには、NVIDIAの「Tesla P100 GPU」を1024基搭載。理論上のピーク性能は4.7ペタフロップス(1ペタフロップスは毎秒1000兆回の浮動小数点演算が可能であることを表す)で、PFNによると民間企業の計算環境としては国内最大規模になる。
PFNでは今後、今回構築したプライベートスーパーコンピュータを活用して、オープンソースの深層学習フレームワーク「Chainer」の高速化を進めると共に、大量の計算資源が必要な交通システムや製造業、バイオヘルスケア分野での研究開発を加速させる。さらに、NVIDIAの次世代GPU「Volta」ベースの「Tesla V100」の導入も検討している。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 世界を変えるAI技術「ディープラーニング」が製造業にもたらすインパクト
世界を変えるAI技術「ディープラーニング」が製造業にもたらすインパクト
人工知能やディープラーニングといった言葉が注目を集めていますが、それはITの世界だけにとどまるものではなく、製造業においても導入・検討されています。製造業にとって人工知能やディープラーニングがどのようなインパクトをもたらすか、解説します。 AI×IoTのブレークスルーを生み出すPreferred Networks、原動力は成長と多様性
AI×IoTのブレークスルーを生み出すPreferred Networks、原動力は成長と多様性
ベンチャー企業のPreferred Networks(PFN)は、時代に先駆けてAIとIoTに着目することで一気に業容を拡大している。同社の原動力になっているのは、創業精神として今も続く「常に新しく技術を取り込んでいく成長」と「多様性」だ。 トヨタがPFNに105億円を追加出資、モビリティ向けAI技術の研究開発を加速
トヨタがPFNに105億円を追加出資、モビリティ向けAI技術の研究開発を加速
トヨタ自動車とPreferred Networks(PFN)は、自動運転技術をはじめモビリティ事業分野におけるAI(人工知能)技術の共同研究・開発の加速を目的に、トヨタ自動車がPFNに約105億円を追加出資することで合意した。 深層学習ソリューションの提供に向けマイクロソフトとPFNが協業
深層学習ソリューションの提供に向けマイクロソフトとPFNが協業
米マイクロソフトとPreferred Networksは、実社会における人工知能や深層学習の活用を推進するため、ディープラーニングソリューション分野で協業することに合意した。 インテルとPFNが協業、「Chainer」のパフォーマンスを大幅に向上へ
インテルとPFNが協業、「Chainer」のパフォーマンスを大幅に向上へ
Preferred Networksが、同社のディープラーニング向けオープンソースフレームワーク「Chainer」の開発で、インテルと協業すると発表。インテルの汎用インフラ上で、Chainerのパフォーマンスを大幅に向上させるのが目的だ。 AIの可能性と限界を理解しよう
AIの可能性と限界を理解しよう
今流行ってるAIは「弱いAI」。「強いAI」ではありません。