東大が医療特化型LLMを開発、医師国家試験の正答率93.3%:医療機器ニュース
東京大学は、日本語医学知識を付与した医療特化型LLMを開発し、対話型AIサービスを公開した。医師国家試験ベンチマークの正答率は93.3%で、OpenAIの「GPT-4o」などの性能を上回った。
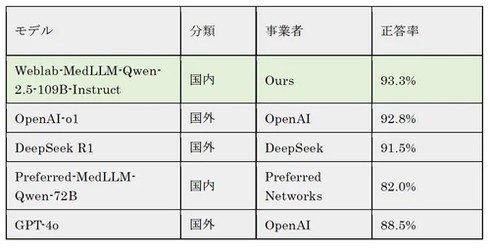
東京大学は2026年3月5日、日本語の医学知識を付与した医療特化型のLLM(大規模言語モデル)を開発し、対話型AI(人工知能)サービスを公開した。2025年医師国家試験ベンチマークで正答率93.3%を記録し、OpenAIの「OpenAI-o1」「GPT-4o」を上回る性能を示した。同サービスは、同年8月31日まで、研究目的限定で研究者向けに提供している。
同モデルは、東京大学大学院工学系研究科技術経営戦略学専攻/附属人工物工学研究センター 松尾・岩澤研究室(松尾研)が、さくらインターネット、ELYZA、ABEJA、理化学研究所および医療機関と連携して開発した。
松尾研では、オープンLLM「Qwen-2.5-72B-Instruct」をベースに、モデルサイズの拡張や医学系コーパスを用いた継続事前学習、指示学習を重ねて「Weblab-MedLLM-Qwen-2.5-109B-Instruct」を構築。既存モデルが保持していない日本国内の医療制度に関する知識を備えており、2025年医師国家試験ベンチマークで正答率93.3%を達成した。外部知識を参照するRAG(Retrieval-Augmented Generation、検索拡張生成)や、多数決方式で精度を高める技術を組み合わせることで、図の参照や計算を要する問題を除き正答率は最大で約98%まで向上する。
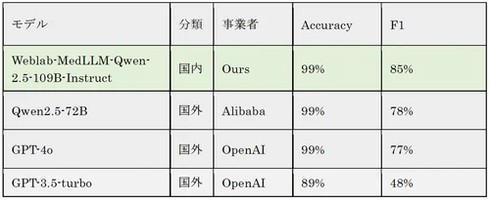
実際の医療現場を想定した電子カルテデータ標準化のユースケース検証では、感染症や検査情報の名称を厚生労働省が定める標準名称に変換するタスクを実施した。
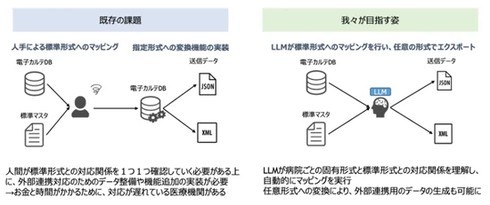
その結果、F1スコア85%の精度で標準名称へ変換が可能であり、国内外の既存LLMの性能を大きく上回った。医学知識を付与したLLMによる標準形式への自動マッピングは、医療データの利活用を促進する可能性がある。
今後は複数の医療機関の電子カルテシステムと連携し、治験患者の探索やレジストリ構築を自動化するLLMエージェントの構築を進める。これにより、労働集約的に実施されている治験患者の探索やレジストリの構築などの業務を効率化し、製薬企業へ任意形式でデータを提供できる体制を整える。なお、公開された対話型AIサービスは研究目的限定であり、診断や治療などの診療行為には利用できない。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 GAFAMに対抗する日本の武器は「現場データ」にあり、JEITAが世界生産額見通し発表
GAFAMに対抗する日本の武器は「現場データ」にあり、JEITAが世界生産額見通し発表
電子情報技術産業協会(JEITA)は2025年版の「電子情報産業の世界生産見通し」を発表した。世界生産額は史上初めて4兆ドルを突破。世界市場の中で日系企業はどう戦うべきか。 TRONが組み込み特化型AIコーディングエージェントを開発、会員に無償提供へ
TRONが組み込み特化型AIコーディングエージェントを開発、会員に無償提供へ
TRONプロジェクトは、組み込みシステム特化型のAIコーディングエージェント「TRON GenAI CODEアシスタント」を開発した。近日中にTRONフォーラム会員向けにβ版を公開し、正式リリース後に同会員は無償で利用できる予定である。 パナソニックHDがマルチモーダルAIの生成速度を倍増、拡散モデルの適用で
パナソニックHDがマルチモーダルAIの生成速度を倍増、拡散モデルの適用で
パナソニックHDは、拡散モデルを応用し、従来比約2倍の生成速度を実現したマルチモーダルAI「LaViDa」を開発。従来の自己回帰型LLMが抱える生成遅延や全体制御の弱さを、独自の高速化技術で克服した。 なぜNTTは「純国産」LLMにこだわるのか、専門知識を強化した「tsuzumi 2」提供開始
なぜNTTは「純国産」LLMにこだわるのか、専門知識を強化した「tsuzumi 2」提供開始
NTTは従来モデルから機能強化したLLM「tsuzumi 2」の提供を開始した。日本語性能や特定業界の専門知識を向上しつつ、引き続き1GPUでの動作を可能にすることでオンプレミス環境への導入のし易さを維持した。tsuzumi 2をNTTグループのAI戦略の中核と据える。 日立は「大規模言語モデルのEMSを目指す」 業務特化型LLMの構築/運用支援開始
日立は「大規模言語モデルのEMSを目指す」 業務特化型LLMの構築/運用支援開始
日立製作所は専門業務に適した大規模言語モデルの構築や継続的な改善などを支援する「業務特化型LLM構築・運用サービス」と実行環境の構築や運用を担う「生成AI業務適用サービス」を開始する。 富士通がCohereと独自LLM「Takane」開発 大企業向けの生成AI提供力強化へ
富士通がCohereと独自LLM「Takane」開発 大企業向けの生成AI提供力強化へ
富士通はエンタープライズ向けのAIを提供するCohereと戦略的パートナーシップを締結することを発表した。