少量の学習データによる次世代AI構築の基盤となる事前学習済みモデル:人工知能ニュース
NEDOと産業技術総合研究所は、動画認識やバイオ分野の自然言語テキストを理解する基盤となる事前学習済みモデルを公開した。少量の学習用データからでも次世代AIのソフトウェアモジュールを構築、利用可能になる。
新エネルギー・産業技術総合開発機構(NEDO)と産業技術総合研究所(産総研)は2019年12月10日、AI(人工知能)を用いた動画認識やバイオ分野の自然言語テキストを理解する基盤となる事前学習済みモデルを構築したと発表した。また同日、同モデルを公開した。
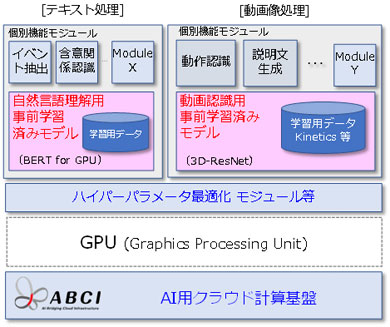
同モデルは、産総研のAI用クラウド計算基盤「ABCI」による大規模な機械学習によって、大量の動画やテキストデータを事前に学習している。
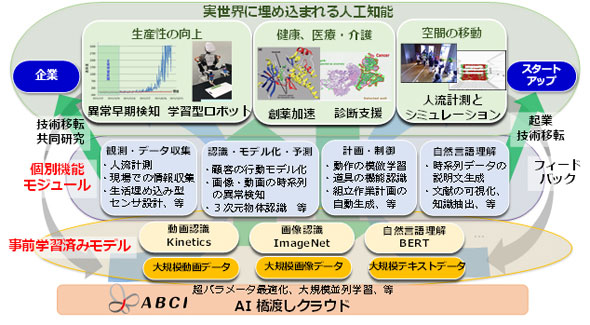
動画を理解するための転移学習の基盤となる事前学習済みモデルは、Google DeepMindのKinetics400データセットを用いて学習させた。このデータセットは、お茶を入れる、絵を描く、ジョギングするなど400種類の日常行動に関する30万本のラベルが付いた短尺動画で、日常生活やスポーツ中の行動を識別できる。
自然言語の理解については、事前学習済みモデルの1つであるGoogleの自然言語処理用モデルBERT(Bidirectional Encoder Representations from Transformers)を用いた。バイオ分野の大規模テキストデータを使って、バイオ分野に特化したBERTを初めから構築。自然言語のテキストは、使われる単語や単語の分布が分野によって異なるため、分野特化型のモデルはバイオ分野の文献から必要な情報を得るのに有効と考えられる。
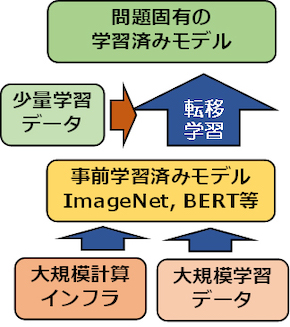
今回構築したモデルを転移学習の基にすることで、動画理解を工場での作業や作業支援ロボットなどへ応用するなど、少量の学習用データからでも次世代AIのソフトウェアモジュールを構築、利用可能になる。
今回開発した事前学習済みモデルに加えて、産総研では、分野特化型BERTが容易に構築できるよう、ABCI上でBERTを学習させるプログラムを公開している。さらに、産総研人工知能研究センターのWebサイトでは、混雑した環境での人流計測や物体の種類と姿勢の同時認識、道具の機能認識などの機能を持った40以上のソフトウェアモジュールと機械学習用データセットを公開している。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 自然言語AIでベテランの暗黙知を活用せよ、その具体策
自然言語AIでベテランの暗黙知を活用せよ、その具体策
デジタル技術による変革が進む中、製造業はどのようなことを考え、どのような取り組みを進めていくべきだろうか。本連載では「AIによる自然言語処理」をメインテーマと位置付けながら、製造業が先進デジタル技術とどう向き合うかを取り上げる。最終回となる第4回では自然言語活用の具体的なポイントを解説する。 AIと機械学習とディープラーニングは何が違うのか
AIと機械学習とディープラーニングは何が違うのか
技術開発の進展により加速度的に進化しているAI(人工知能)。このAIという言葉とともに語られているのが、機械学習やディープラーニングだ。AIと機械学習、そしてディープラーニングの違いとは何なのか。 機械学習はどうやって使うのか――意外と地道な積み重ね
機械学習はどうやって使うのか――意外と地道な積み重ね
前編では、AI(人工知能)と機械学習、ディープラーニングといった用語の説明から、AIを実現する技術の1つである機械学習が製造業を中心とした産業界にも徐々に使われ始めている話をした。後編では、機械学習を使ったデータ分析と予測モデル作成について説明する。 機械学習で入ってはいけないデータが混入する「リーケージ」とその対策
機械学習で入ってはいけないデータが混入する「リーケージ」とその対策
製造業が機械学習で間違いやすいポイントと、その回避の仕方、データ解釈の方法のコツなどについて、広く知見を共有することを目指す本連載。第1回では「リーケージ」について取り上げる。 機械学習による逆問題への対処法、材料配合や工程条件を最適化せよ
機械学習による逆問題への対処法、材料配合や工程条件を最適化せよ
製造業が機械学習で間違いやすいポイントと、その回避の仕方、データ解釈の方法のコツなどについて、広く知見を共有することを目指す本連載。第2回は、製造業で求められる材料配合や工程条件の予測に必要な、機械学習による逆問題への対処法ついて取り上げる。 教師データが足りないと「異常予測」は難しい、ならば「異常検知」から始めよう
教師データが足りないと「異常予測」は難しい、ならば「異常検知」から始めよう
製造業が機械学習で間違いやすいポイントと、その回避の仕方、データ解釈の方法のコツなどについて、広く知見を共有することを目指す本連載。第3回は、「異常予測」と「異常検知」について取り上げる。教師データ量の不足が課題になる「異常予測」に対して、「異常検知」は教師データなしでも始められることが特徴だ。