tarファイルに魔法をかけてみよう! その1 = tarfsのデータ構造 =:作りながら理解するファイルシステムの仕組み(4)(1/2 ページ)
今回と次回の2回に渡って、「tarfsのデータ構造」と「ファイルシステムとしてマウントするまでの処理の流れ」について解説
以前、新入社員に、「tarファイルシステム」の試作モジュールを使って、「tarファイル」を通常のデバイスのようにマウントし、tarファイル内のファイルをLinuxコマンドで快適にアクセスするデモを見せたところ、
「tarファイルにどんな魔法をかけたのですか?」
と、非常にうれしい反応を返してくれました。
この魔法の仕掛けは、連載第3回「ファイルシステムってそんなに簡単に作れるの?」で、一通り説明しましたが、ポイントは“tarファイルの終端にメタデータを配置する”という、大胆ですがチャレンジングな方法を採用した点にあります。
そこで、今回と次回の2回にわたって、「tarfsのデータ構造」と「ファイルシステムとしてマウントするまでの処理の流れ」について解説していきます。
まず今回は、tarfsのデータ構造について見ていきましょう。tarfsのメタデータとしては、基本的に、連載第2回「素晴らしきファイルシステムのデータ管理」で説明したメタデータの構成をほぼ踏襲しています。ただし、データ構造が複雑になるものについては、説明を省略していたものがありましたし、tarファイルシステム固有のデータ構造もありますので、今回はこれらについて重点的に説明していきたいと思います。
tarfsのデータレイアウト構造
はじめに、tarfsのデータ構造の全体イメージを紹介します。図1をご覧ください。

図1を見て分かるとおり、メタデータはtarファイルの終端以降に配置されています。ここで、「スーパーブロック」がファイルの終端に配置されている点に気が付かれたでしょうか?
通常なら、スーパーブロックは先頭に配置しますが、これだとtarファイルを壊してしまいます。よって、先頭ではなく、終端にスーパーブロックを配置することにしました(注1)。また、ファイルシステムのデータアクセスの基本単位となる「ブロックサイズ」ですが、実装を単純化するために、tarファイルの管理単位である512bytesを採用しています。
図1では、「inode管理領域」「ディレクトリデータ管理領域」「間接エクステント管理データ領域」の各領域がきれいに分かれています。しかし、正確には図2に示すように、128kbytes単位で各メタデータ領域が散らばった構造になっています。
個々のメタデータ領域が“散らばった状態”は、望ましいものとはいえません。可能なら、これらをひとまとめにしたいところですが、メタデータ構築時間をできるだけ短縮させるため、そのようにしませんでした。
各メタデータ領域をひとまとめにするには、最初にtarファイルをすべてパースし、inode総数、ディレクトリデータ総数などをカウントします。そして、各領域の必要サイズを計算し、それぞれ割り当てる必要があります。この場合、全体として2回のパース(必要領域計算時とメタデータ構築時)が発生するので、処理時間が2倍になってしまいます。
よって、tarファイルのパースとメタデータの構築を同時に行うために、“必要なときに必要なメタデータを動的に獲得する”ようにしました。ただし、1個ずつ(512bytes)メタデータを獲得していたのでは、散らばり具合が大きくなり過ぎるため、ある程度まとまった量(256個分:128kbytes)のメタデータ領域を獲得し、メタデータの分散を低減させるようにしました。これが図2のような構造になる理由です。
tarfsの管理データ
tarfsが管理するデータには、以下のようなものがあります。
以下では、inode、ディレクトリデータ、間接エクステント管理データについて詳しく見ていきます。そして、これらのメタデータがスーパーブロックからどのようにアクセスされるのかを説明していきます。
inode
tarファイルの中には、inode情報があります。しかし、以下に示す2つの理由により、専用のinodeを新たに定義することにしました。
理由1:
tarファイルのinodeのデータは、ASCIIコードであるため、Linuxカーネルの処理において、毎回バイナリコードに変換するとオーバーヘッドが大きくなる可能性がある。
理由2:
エクステントデータ情報は、tarファイルのinodeには存在しない。
ただし、シンボリックリンクファイル名やユーザーデータについては、tarファイル内にあるデータをそのまま使用した方が効率的であるため、tarfsのinodeからtarファイルのinodeを参照できるようにします。
表1に、tarfsのinode情報を示します。
| inodeの情報 | メンバのデータサイズ(bytes) | 意味 | |
|---|---|---|---|
| マジック番号 | 8 | tarfs inodeのマジック番号 | |
| ファイルタイプ/モード | 4 | ファイルタイプとファイルモードの論理和 | |
| 所有者番号 | 4 | ファイル所有者であるユーザーのID | |
| グループ番号 | 4 | ファイル所有者であるユーザーのグループID | |
| リンク数 | 4 | ファイルの名前の数 | |
| ファイルサイズ(byte) | 8 | ファイルのサイズ | |
| ブロック数(block) | 8 | このファイルに登録されているデータのサイズ | |
| ファイル参照時刻 | 8 | ファイルのデータを参照した時刻 | |
| ファイル更新時刻 | 8 | ファイルのデータを更新した時刻 | |
| inode更新時刻 | 8 | inodeを更新した時刻 | |
| tarファイルのinode位置(block) | 8 | tarファイル領域のinodeのオフセット | |
| エクステント数 | 8 | このinodeに登録されているエクステントの総数 | |
| エクステント情報[17] | 408(17*24) | このinodeに登録されているエクステント。最大で17個のエクステントが登録される | |
| 間接エクステント位置 | 8 | このinodeに登録し切れなかったエクステントを管理する間接エクステント管理データ領域のオフセット | |
| フラグ | 4 | inodeのフラグ(現在、未使用) | |
| パディング | 12 | 未使用領域 | |
| 表1 tarfsのinode情報 | |||
tarfsのinodeの中で使用されているエクステント情報は、表2に示すとおりです。
| エクステント情報 | メンバのデータサイズ(bytes) | 意味 | |
|---|---|---|---|
| 論理オフセット(block) | 8 | ファイル内の論理オフセット | |
| 物理オフセット(block) | 8 | tarファイル内のオフセット | |
| エクステントサイズ(block) | 8 | エクステントの長さ | |
| 表2 tarfsのエクステント情報 | |||
ディレクトリデータ
tarファイル内には、ファイルパス名は存在しますが、ディレクトリ内に存在するファイル名を構造化して登録しているデータは存在しません。これだと、ディレクトリ配下に存在するファイルの検索において、毎回、個々のファイルパスをパースしていかなければならず、処理効率が悪くなります。このため、tarfsのメタデータとして、ディレクトリデータを構築することにしました。
tarfsのディレクトリデータは、ブロックサイズに合わせて、512bytes単位で管理します。そして、このディレクトリデータでは、複数のファイル名を登録することになりますが、一般的に個々のファイル名はそれぞれ異なるファイル名長を持ちます。よって、このようなデータを管理するために、「ディレクトリエントリ」という可変長データ構造を使用することにしました(注2)(表3)。
| ディレクトリエントリ情報 | メンバのデータサイズ(bytes) | 意味 | |
|---|---|---|---|
| ファイルのinode番号 | 8 | ファイル内の論理オフセット | |
| レコード長 | 2 | このディレクトリエントリ全体の長さ | |
| ファイル名長 | 2 | ファイル名の長さ | |
| ファイルタイプ | 1 | ファイルタイプ ・通常ファイル:1 ・ディレクトリ:2 ・シンボリックリンク:3 |
|
| ファイル名 | 1〜255 | ファイルの名前(可変長:最大で255文字) | |
| 表3 ディレクトリエントリ情報 | |||
ここで、例として、3つのファイル「test_file_A(ino=10)」「dir_B(ino=11)」「sym(ino=12)」を管理する場合のディレクトリエントリのデータ配置状況を示します(図3)。
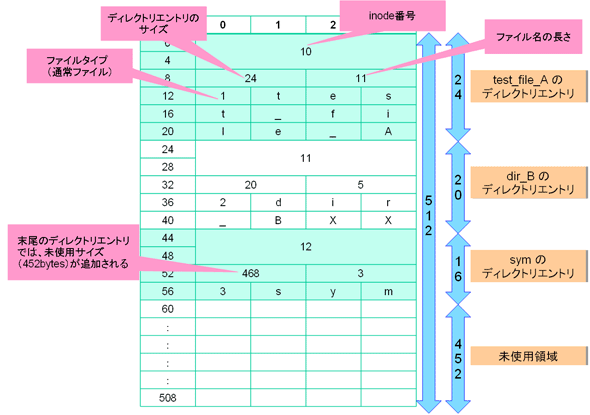
このディレクトリデータに対して、“sym”というファイル名の存在を確認する流れを以下に示します。
- まず、0バイト目のディレクトリエントリをチェックする。
- ディレクトリエントリの名前(test_file_A)が“sym”と一致しないので、レコード長(24)だけオフセットを進める。
- 24バイト目のディレクトリエントリをチェックする。
- ディレクトリエントリの名前(dir_B)が“sym”と一致しないので、レコード長(20)だけオフセットを進める。
- 44バイト目のディレクトリエントリをチェックする。
- ディレクトリエントリの名前(sym)が“sym”と一致する。
ここで、“sym”のディレクトリエントリのレコード長「468」が、実際のレコード長「16」よりも大き過ぎることに気が付いたでしょうか? このように、ディレクトリエントリのレコード長が、実際のレコード長よりも大きい場合は、このレコードに“未使用データがある”ことを意味します。このケースでは、452bytesが未使用であることを示しており、さらにディレクトリエントリを追加することが可能です。例えば、新たに「test1(ino=13)」というファイルを追加すると、図4のようになります。
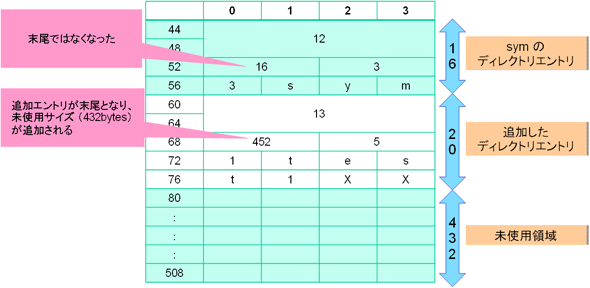
基本的に、この方法でファイル名を追加できますが、大量にファイル名を追加していくと、いずれ未使用領域が不足してしまいます。その場合は、新たにディレクトリデータ(512bytes)を追加することで対応します。
Copyright © ITmedia, Inc. All Rights Reserved.