素晴らしきファイルシステムのデータ管理:作りながら理解するファイルシステムの仕組み(2)(1/2 ページ)
ファイルシステムが一体どうやってデータを管理しているのか? 単純な例を挙げながらその仕組みを詳しく解説しよう
私たちは普段、携帯電話やデジタルカメラで何げなく画像データなどを保存していますが、それらのデータが一体どこに・どんなふうに管理されているのか、あまり意識することはないと思います。これもファイルシステムが、あなたのデータ管理をすべて引き受けてくれているおかげです。
前回「ないと困る!? ファイルシステムのありがたみ」では、ファイルシステムのない世界をご紹介し、そのありがたみについて再認識しました。今回は、そのありがたいファイルシステムが一体どうやってあなたのデータを管理しているのかについて、単純な例を挙げながらその仕組みを解説したいと思います。
メタデータ
ファイルシステムは、あなたのデータの配置状況をメモ書きして忘れないようにしておく必要があります。例えば、前回の例にあった記事1〜3を考えてみると、HDD内で使用している領域、および使用していない領域(未使用の領域)をすべてメモする必要があります。そうしないと、HDDの全領域をフルに使用することはできません。また、ユーザーのファイル、およびそのファイルの名前を管理するディレクトリの配置先もメモしておかないといけません。
このように、ファイルシステムはすべてのデータにアクセスする必要があるため、HDD内の“地図”を必要とします。この地図のことを、“データを管理するためのデータ”という意味で「メタデータ」といいます。ファイルシステムは、非常に多種多様なもの(表1)が世に出ていますが、このメタデータのフォーマットがファイルシステムの特徴を決定するといっても過言ではありません。
| Linux | ufs、ext2、ext3、ext4、reiserfs、btrfs、jfs、xfs、gfs2、ocfs2、jffs2、ubifs…… |
|---|---|
| Windows | fat、ntfs…… |
| 表1 ファイルシステムの種類 | |
メタデータの設計は、ディスクの性能や空間効率などを考慮して行うべきものですが、本稿ではファイルシステムのデータ管理のエッセンスを理解してもらうことを目的としているので、できるだけメタデータ構造は単純化して説明していきます。そのため、ファイルシステム内に存在するファイルの種類も以下の2種類だけとします。
- 通常ファイル
- ディレクトリ
メタデータの説明に入る前に、前提知識となる「ブロックサイズ」についてお話ししておきます。ブロックサイズとは、ファイルシステムがHDDのデータを管理するためのサイズのことで、以下のようにHDDをある固定のサイズ単位で分割して管理しています。
そして、分割された各ブロックには、先頭から順番に番号が振られます。この番号は、HDD内のデータにアクセスするための住所のようなもので「物理オフセット」といいます。なお、このブロックサイズはファイルシステムによってさまざまであり、一般的には、OSのページサイズに合わせているものが多いです。そして、ファイルシステムは、このブロックサイズ単位で「データの検索」「読み込み」「書き込み」を行います。
スーパーブロック
はじめに、ファイルシステムはすべてのデータにアクセスできるように、各データがどのようなレイアウトになっているのかを知っておく必要があります。そのデータを管理する領域をHDDの先頭に配置します。この領域は、すべてのデータへアクセスするための基点となる重要なデータであり、「スーパーブロック」といいます。
この領域には、以下のデータがHDDのどこにあるのかが記録されています(図2)。
また、スーパーブロック内には、このようなレイアウト情報だけでなく、データの使用状況などの情報もあります。これらのイメージを具体的につかんでもらえるように、mkfs直後のスーパーブロックの中身を見てみましょう(図3)。

この例では、説明を単純にするため、ブロックサイズを1kbytesとしています。以降、ブロックサイズ単位のデータには、(block)と付けています。ファイルシステム全体のサイズは、ファイルシステムサイズで表されており、1000ブロックです。このうち、1ブロックはこのスーパーブロックが占有しています。
使用中のユーザーデータ量は、mkfs直後なので0になります。総ファイル数は、作成できる最大ファイル数であり、100個です。そして、使用中のファイル数は、ルートディレクトリが存在しているため1個になります。
残りは、各データ領域のレイアウトを示しています。まず、空きデータ領域の物理オフセットは、スーパーブロックの次からはじまるので、1ブロック目で、そのデータサイズは99ブロックです。空きデータ領域の次は、inode管理領域であり、その物理オフセットは100ブロック目、サイズは100ブロックです。inode管理領域の次は、ディレクトリデータ領域であり、その物理オフセットは200ブロック目、サイズは100ブロックです。そして、最後はユーザーデータ領域で、その物理オフセットは300ブロック目、サイズは全データ領域の中で一番大きく700ブロックです。
空きデータ管理領域
mkfsを実行した直後は、各データ領域は大半が未使用状態(注3)です。このようなデータ領域を管理するのが、空きデータ管理領域の役割です。今回の場合は「inode」「ディレクトリデータ」「ユーザーデータ」と3種類のデータを管理する必要があるため、空きデータ領域を下図のように3等分して管理することにします。
次に、空きデータの配置状態を管理するためのデータとして、ここでは「エクステント」というデータを使います。エクステントとは、さまざまなファイルシステムで使われているデータ構造であり、物理的に連続しているデータを表現するものです。なお、図5は連続しているデータのイメージを示したものです。
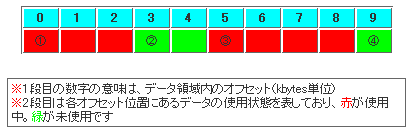
この例では、全部で4つの領域(①②③④)があることが分かります。連続しているデータのイメージとは、このような同じ色の集まりのものです。そして、この連続データの配置状態を表現するなら、そのデータの開始位置(オフセット)と連続しているデータの個数(サイズ)があれば十分です。例えば、①の場合は{オフセット=0、サイズ=3}となります。②の場合は{オフセット=3、サイズ=2}となり、③の場合は{オフセット=5、サイズ=4}。そして、④の場合は{オフセット=9、サイズ=1}となります。
この{オフセット、サイズ}の組み合わせがエクステントのデータ構造というわけです。
これらのエクステントのうち、未使用である領域は図5の緑の領域であり、②と④のところです。よって、空きデータ領域には、これら2つのエクステントを登録しておけばよいことになります(図6)(注4)。
| 空きデータ領域内のエクステント | オフセット(block) | サイズ(block) | |
|---|---|---|---|
| エクステント1 | 3 | 2 | |
| エクステント2 | 9 | 1 | |
| 図6 空きデータ管理領域のエクステント配置状況 | |||
inode管理領域
前回、ファイルは名刺のようなものと説明しましたが、その名刺に当たるデータを管理するのが、「inode」というデータです。inodeの具体的なデータは図7に示すとおりです。
| inodeの情報 | 意味 | |
|---|---|---|
| ファイルタイプ | 通常ファイル、ディレクトリを識別するためのフラグ | |
| ファイルモード | ファイルアクセス権(読み込み権、書き込み権、実行権) | |
| 所有者番号 | ファイル所有者であるユーザーのID | |
| グループ番号 | ファイル所有者であるユーザーのグループID | |
| ファイルサイズ(byte) | ファイルのサイズ | |
| ファイル参照時刻 | ファイルのデータを参照した時刻 | |
| ファイル更新時刻 | ファイルのデータを更新した時刻 | |
| inode更新時刻 | inodeを更新した時刻 | |
| リンク数 | ファイルの名前の数 | |
| ブロック数(block) | このファイルに登録されているユーザーデータのサイズ | |
| データ管理情報 | このファイルが管理するデータ(※)の領域情報 ※通常ファイルの場合は、ユーザーデータ領域。ディレクトリの場合は、ディレクトリデータ領域 |
|
| 図7 inodeデータ | ||
Linuxでは、上記のメンバのうちデータ管理情報を除くほぼすべての情報を、statコマンド(注5)で確認できます。それでは実際に見てみましょう。
以下は通常ファイルに対して、statコマンドを実行した結果です。
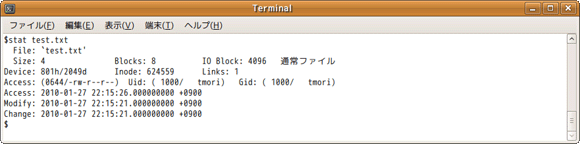
まず、ファイルタイプは「通常ファイル」と表示されているので一目瞭然です。そして、inode情報として表示されているものについては、以下のとおりです。
- Size:ファイルサイズ
- Blocks:ブロック数(注6)
- Links:リンク数
- Access(1個目):ファイルモード
- Uid:所有者番号
- Gid:グループ番号
- Access(2個目):ファイル参照時刻
- Modify:ファイル更新時刻
- Change:inode更新時刻(注7)
次に、ディレクトリに対して、statコマンドを実行した結果は以下のとおりで、ファイルタイプはディレクトリとして見えます(注8)。
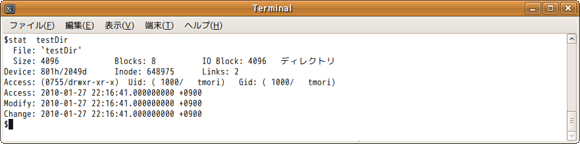
ここまでの説明で、inodeのおおよそのイメージはつかめてきたのではないかと思います。
このinodeは、ファイルやディレクトリを作成すると「inode領域」に割り当てられます。例えば、前回のファイルシステム操作で紹介したファイル(ルートディレクトリ、lost+found、article_1、article_2、article_3)を管理する場合、各ファイル、ディレクトリのinodeは、以下のような配置になります(図8)。
ファイルシステムは、各inodeに「inode番号(ino)」という固有の番号(注9)を振ります。このinode番号は、inode領域の中での住所の役割をしており、ファイルシステムはinode番号を基に、対象inodeの検索を行います。例えば、article_3のinoは5ですが、このinodeの検索はinode領域の先頭から5個目の領域をアクセスするというもので、単純でかつ高速な検索が可能になっています。
Copyright © ITmedia, Inc. All Rights Reserved.