ないと困る!? ファイルシステムのありがたみ:作りながら理解するファイルシステムの仕組み(1)(1/2 ページ)
ファイルシステムの仕組みとは? まずは、当たり前のように使っているファイルシステムのありがたみを再認識しよう
筆者は、昨年11月に開催された「組込み総合技術展 Embedded Technology 2009(ET2009)」で、組み込み開発者の“熱気”を肌で感じてきた1人ですが、特に「Android」「Linux」の盛り上がりはすごいと感じました。われわれの身近なところでいうと携帯電話がまさにその流れにあり、LinuxやAndroidが採用されています。最近、筆者の周りにも、いわゆるGoogle携帯を愛用している若手社員がちらほら見られます。
あるとき、筆者はGoogle携帯を楽しそうに操作している若手社員にこんな質問をしてみました。
――その携帯、OSは何が入っているの?
即、「Linuxですよ。Androidっすよ!!」(若手社員)という返事が返ってきました。
――へー。そうなんだ。で、ファイルシステムは何が入っているの?
「え? ……」(若手社員)でした。
組み込み分野では、システムの資源の制約が厳しく、ファイルシステム自体がなかったり、あったとしてもROM用・省スペース用のものだったりしますが、ユーザーはそのファイルシステムを意識することはまずありませんよね。また、開発者にとっては、OSとして組み込みLinuxを使っていれば、ファイルシステムは豊富にあるので、自ら作る必要性に迫られることはありません。そのため、あらたまってファイルシステムの役割や仕組みを意識する機会というのは少なくなってきているのではないでしょうか。
そこで、本連載では、専門用語はなるべく控えて、ファイルシステムの役割・仕組みのエッセンスを解説していきます。また、より理解を深めるため、筆者がオリジナルのファイルシステムを試行錯誤しながら実際に作ってみた過程を紹介していきます(注1)。ここで紹介するファイルシステムとは、tarアーカイブファイル(注2)を展開しなくてもマウントするだけで、アーカイブ内のファイルを参照できるようにするものです。これをLinuxの「Ubuntu 9.04(カーネルバージョンは2.6.28)」上で実現していきます。
ファイルシステムが必要な理由
誰しもパソコン上で、文章を書いたことがあると思います。文章の作成・編集が終わった後、「名前を付けて保存」を選び、任意の名前を付けてファイルに保存できますし、その文章をもう一度読みたくなったら、エディタでそのファイルを指定して開くだけで気軽に読むことができます。
あなたは、これら一連の操作の中で、自分が書いた文章がHDDのどこに書き込まれ、どこから読み込まれるのかを気にする必要はありません。
これこそが、ファイルシステムの役割なのです。
ここで、ファイルシステムのありがたみを知るためにも、ファイルシステムがない世界(HDDに直接データの書き込み・読み込みをする世界)を考えてみましょう。
ビジネスマンAさんのお仕事は、大量のビジネス文章を作成することです。そして、Aさんには今週の課題として3本記事を書く必要があり、月末に記事を公開します。
月曜日、Aさんはいつもどおり出社し、1本目の記事を書きはじめました。この日は仕事がはかどり、1本目の記事を書き終え、その文章データ(10kbytes)をHDDに保存することにしました。Aさんのパソコンには新品のHDDが搭載されており、本日書き上げた記事をHDDの先頭に10kbytes分だけ書き込みました(図1)。
火曜日、Aさんは2本目の記事に取り掛かりました。2本目の記事は内容豊富で量も多く、一通り文章が出来上がってみると、記事のデータ量は50kbytesになりました。2本目の記事のHDDへの書き込み個所は、記事1の次に当たる10kbytesからです(図2)。
水曜日、Aさんは3本目の記事を書きました。そのデータ量は30kbytes。現状、HDDの60kbytesのところまで大切なデータが入っているので、60kbytesのところからデータを書き込みました(図3)。
木曜日、Aさんは3本の記事を課長に提出し、レビューしてもらいました。このとき、1本目の記事には内容として漏れが多く、大幅な手直しが入りました。
金曜日、Aさんは1本目の記事の手直しを行い、データ量が50kbytesに膨れ上がりました。そのデータを、HDDの元あった場所に戻してしまうと、火曜日に書いた記事2が消えてしまいます。そこで、90kbytesのところから書き込みすることにしました(図4)。
こうして、Aさんは今週の課題をクリアできました。そして、月末、Aさんは1本目の記事を取り出そうとしました。
「あれ? 1本目の記事を保存したのはどこだっけ? 古いのしか見当たらないぞ!?」(Aさん)。
こんな情景が目に浮かびます。Aさんは、自分が書いた記事がHDDのどこにあるのかをきちんとメモしておくべきでしたね。この例では、それほど多くの文章を保存していませんが、もっと大量のデータだったら……。
ファイルシステムがあると、文章を保存するときにHDDのどこにデータを書き込むのかということを気にしないで済みます。また、保存した文章がHDDのどこに配置されているかを気にしなくて済みます。なぜなら、ファイルシステムがこれらのことをやってくれているからです。ありがたいですね。
ファイルシステム操作
さて、今度はファイルシステムを使って、記事1→記事2→記事3の順番で記事の作成を行った後、記事1のデータ量を元より大きくする操作をしてみましょう。一連の操作の中に、HDDのどこを読み書きすればよいのかを気にする必要があるでしょうか? 編集後の記事1はちゃんと見られるでしょうか? 記事2のデータは消えてしまわないでしょうか?
確認してみましょう。
なお、ここで使用するファイルシステムは、Linuxのext4(注3)を利用します。
前提知識
早速、記事を作りたいところですが、その前に、ファイルシステムの話をするうえで欠かせない基礎知識について解説します。
・ファイル
ファイルシステムでは、個々のユーザーデータを「ファイル」として管理します。ファイルは、名刺みたいなもので、名前・所属・連絡先と同等の情報を持っています。例えば、前節の記事1について見てみると、以下のようなデータを管理することになります。
| 記事の名前 | 記事1 |
|---|---|
| 記事の所有者 | Aさん |
| 記事の配置場所 | HDDの90〜140kbytes |
・ディレクトリ
名刺の数が増えると、ちゃんと分類して管理しておかないと、どこに何があるのか分からなくなりますよね。それと同じように、ファイルシステムでもファイル数が多くなると整理したくなります。ファイルシステムは、その整理のために「ディレクトリ」という特殊なファイルを用意しています。ディレクトリは、図5のような階層構造で、その頂点にいるディレクトリを「ルートディレクトリ」といいます。
/ ……ルートディレクトリ:配下にarticle、movie、musicディレクトリがある
├ article ……articleディレクトリ:配下にarticle_1〜3のファイルがある
│ ├ article_1
│ ├ article_2
│ └ article_3
├ movie ……movieディレクトリ:配下にmovie_1、movie_2のファイルがある
│ ├ movie_1
│ └ movie_2
└ music ……musicディレクトリ:配下にmusic_1、music_2のファイルがある
├ music_1
└ music_2
| 図5 ディレクトリの階層構成 |
ディレクトリもファイルですので、自分の名刺を持っており、以下のようなデータを管理することになります。
| ディレクトリの名前 | |
| ディレクトリの所有者 | |
| ディレクトリ配下に存在するファイル名一覧 |
セットアップ
ファイルシステムを実際に使うためには、データを記録するためのデバイスを初期設定する必要があります。ここで使用するデバイスとしては、手ごろなフラッシュメモリ(注4)を使ってみます。パソコンにフラッシュメモリを挿すと、Linuxは、そのフラッシュメモリを認識し、デバイス管理用のディレクトリ(/dev/disk/by-id)から参照できます。
今回使用した環境では、以下のように認識されます。
/dev/disk/by-id/usb-BUFFALO_USB_Flash_Disk_A400000000187817-0:0-part1
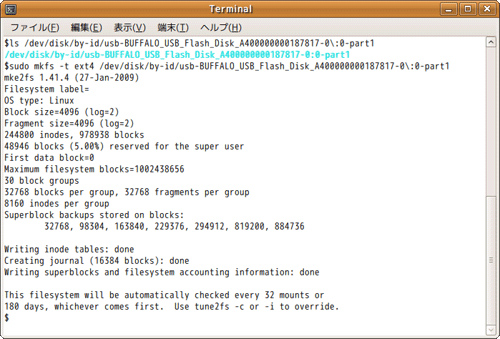
ファイルシステムを初期設定するのは、mkfs(注5)コマンドです。それでは、mkfsコマンドでフラッシュメモリを初期設定してみましょう。
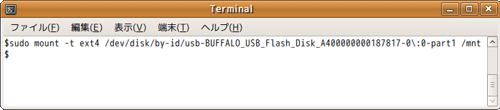
続いて、Linuxにこのデバイスをファイルシステムとして認識させる必要があります。そのためのコマンドはmount(注6)コマンドです。
これで、ファイルシステムを使うための準備が完了しました。
ディレクトリ操作
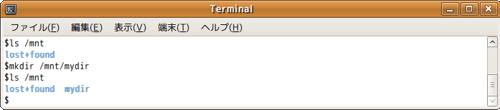
mkfsを実行し、マウントした直後はルートディレクトリとlost+found(注7)ディレクトリしかありません。まずは、自分のデータを管理するための専用のディレクトリ(今回は“mydir”としました)を作りたいですよね。それを実行するコマンドが、mkdirです。また、ディレクトリ内に存在するファイル一覧を見たいときは、lsコマンドを使用します。
Copyright © ITmedia, Inc. All Rights Reserved.