限界に達したエンベデッド・プロセッサを並列処理で補完する:SYSTEM DESIGN JOURNAL(3/4 ページ)
組み込みシステムの能力を並列処理で補完するアイデアは、身近で現実味を帯びたものとなっています。しかし、その実行に際しては手法の選択が重要な意味を持ちます。OpneMPやOpenCLなどを理解しながら、最適な手法を検討しましょう。
OpenCLの概要
スーパーコンピュータ業界が中心で取り組んでいたOpenMPとは別に、Appleも極めて異なる背景で並列コードの課題の研究に着手していました。
Appleのチームは多くのCPUコアが仮想メモリを共有するシステムではなく、1個のCPUに幾つかのハードウェアアクセラレータに取り付ける、小規模な非対称アーキテクチャでの並列化に取り組みました。つまり、対象はスーパーコンピュータではなく、パーソナルコンピュータだったのです。「CPU+GPU SoC」の方式を考えていたインテル、NIVIDA、AMDがその取り組みに参加するのに時間はかかりませんでした。そうしてでき上がったものが OpenCL (Open Computing Language)でした。
OpenMPと同様に、OpenCLも並列化のためのプラットフォームを提供します。OpenMPとは異なり、OpenCLはローカルメモリをベースにして明確に定義されたメモリ階層に各プロセッサがアクセスする、ヘテロジニアスな環境を想定しています(図 2)。
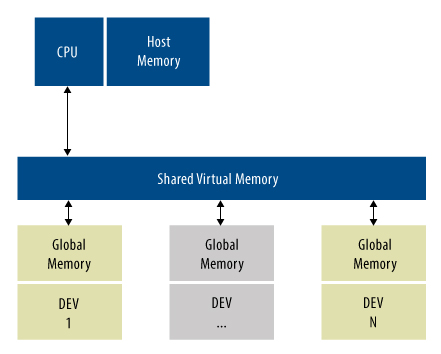
ただ、OpenMPとは異なり、OpenCLではCコードの一部を幾つかのエクステンションを持つサブセットに変換する必要があります(FORTRANのプログラマには関係ありません)。制限が厳しい言語で書き直さなければならない代わりに、OpenCLプラットフォームはコードの並列部分を変換して、サポートされるアクセラレータハードウェアで実行できるようにしてくれます。今日、そのリストには、幾つかのGPU、マルチコアDSP SoC、FPGA、固定機能アクセラレータ(ビデオプロセッサなど)、またはこれらのデバイスの混合物が含まれます。
OpenCLの開発フローはOpenMPのそれとはかなり異なっています。プラグマで区切った1つのプログラムではなく、一連のプログラムとして開発するのです。OpenMPのマスタースレッドに相当するメインプログラムは、C/C++、Python、Java、またはあまり有名でない言語の1つで記述します。これは多くの場合、数個のセグメントを取り外してAPIコールで置き換えたレガシープログラムに過ぎません。このホストプログラムをOpenCL APIライブラリとともに通常通りコンパイルし、ホストCPU上で実行します(OpenCL はホモジニアス・マルチコア・ハードウェアでも使用できますが、その考えはホスト CPU とコプロセッサを指向していることに注意してください)。
高速化しようとするコード部分(OpenMPのプラグマでフラグを立てた要素)は、CのOpenCLの記法に沿って別の小さなプログラムとして書き直します。その小さなプログラムはカーネルと呼ばれます。メイン・プログラムは、その前のパラグラフで挿入したOpenCL APIコールでカーネルを呼び出します。
OpenCLプラットフォームは、実行時に使用可能なハードウェアかどうかを調べます。使用できるアクセラレータがない場合は、カーネルがメインCPU(インテルまたはAMDアーキテクチャのもの)をアクセラレータとして使用することがあるため、基本的には元のシングルスレッドプログラムが得られます。
利用できるハードウェアがあれば、OpenCLはそれを利用するカーネルをコンパイルします。それには、ループ展開またはベクトル分解オペレーションと、その結果として得られたスレッドを複数のCPUコアまたは GPU の多くの小さなプロセッサの全体に分散させる場合があります。また、カーネルの入力データをSoCやFPGAの固定関数アクセラレータにバインドすることを意味することもあります。メインプログラムを実行するとカーネルが呼び出され、次にカーネルがアクセラレータ上で実行されます。
FPGA用のOpenCLツールは、カーネルをVerilogにコンパイルしてFPGA用のハードウェアアクセラレータを実行前にオフラインで合成できるため、FPGAは興味深い特別なケースになります。
実行時にはOpenCLドライバがアクセラレータをFPGAにロードし、カスタムハードウェアを作成すると、多くの場合に命令のフェッチとデコード、さらには内部データの移動をなくし、従来のCPUでは不可能だったかもしれないきめ細かな並列処理を利用することができます。
OpenCLの仕様には、最初のリリース以来多くの追加が行われてきました。その中には、データタイプの追加、メモリ機構の柔軟性向上、大規模なGPUやFPGAなどをいくつかの異なるアクセラレータに分配する機能、プログラムからバッファをなくして入力データをアクセラレータ経由で直接流せるようにするパイプの追加などがあります。
Copyright © ITmedia, Inc. All Rights Reserved.