テーブルやインデックスをどうやって管理しているの?:組み込みDBプログラミングの道しるべ(3)(2/2 ページ)
「システムテーブル」には、データベースに含まれるすべてのテーブル、インデックスなどのスキーマ情報が含まれている。
高速でデータを検索するインデックス
前述の解説で、システムテーブルでスキーマ情報を管理していることが分かりましたので、次にインデックスについて説明します。
インデックスはその名のとおり、“索引”です。検索したいデータをある特定のキー情報を使って検索します。例えば、郵便番号テーブルがあり、そのテーブルには郵便番号と対応する住所が入っているとします。郵便番号にキーを設定していくことで、郵便番号をキーに該当する住所を検索できるわけです。
では、インデックスにはどのような種類があるのでしょうか。以下に、一般的に組み込みデータベースで利用されているインデックス技術を示します。
- Bツリー(Balanced Tree)
二分木ともいう。データ構造の1つで、根付きツリー構造の中で、ある親ノードが持つ子の数が2以下であるものをいう。データベースで利用されているBツリーはBツリーを改良したB+ツリーやB*ツリーが一般的である。 - Rツリー(Rectangle Tree)
Bツリーに似た木構造のデータ構造であり、多次元情報のインデックス付けで空間インデックスなどに使われる。地図情報の施設情報(POI:Point Of Interest)の検索などで利用されている。 - ビットマップインデックス
キーが取り得る値の少ない性別(男=0、女=1の2つ)のときには、Bツリーインデックスだと深さがないため、同一キーのデータ個数が多くなり役に立たない。このような場合にはビットマップインデックスが有効。性別なら1ビット、例えばカテゴリが8つあれば3ビット(2の3乗)で済み、インデックスデータをすべてメモリ上に展開できるため、高速に処理できるという利点がある。 - N-Gramインデックス
N文字インデックスとも呼ばれ、文字をグラムという単位で分割してインデックスを作成することで文字の検索を実現する。例えば、N=2なら2-gramということで、2文字の集合として処理する。一般的にN-gramインデックスは全文検索エンジンなどで利用される。組み込みデータベースでもEntierのようにこの技術を使って高速に部分一致検索を実現している製品も存在する。
このほか、これらのインデックス技術を利用し、特定の機能を実現したインデックスも存在します。
例えば、Entierの場合では“絞り込み検索(インクリメンタルサーチ)”を実現するための「絞り込みインデックス」という機能が提供されています。このインデックスはタッチパネルなどでひらがなを1文字ずつ選択したタイミングで、絞り込んでいくときなどに利用されるものです。SQLに慣れている方であればLIKEオプションを利用すれば実現できると思いますが、LIKEオプションではインデックスが利用される逐次検索(テーブルスキャン)となってしまうため、絞り込みに時間がかかり、利用者にストレスを与えてしまいます。Entierの場合は、候補文字を与えるとそれに該当するデータの数と次の候補文字を返すAPIが用意されています(図3)。
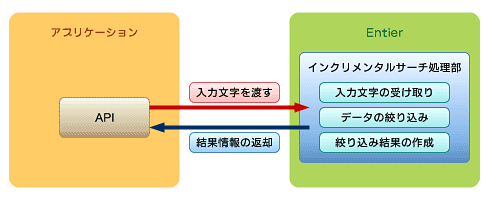
絞り込みインデックスの作成には、CREATE INDEX構文でINCREMENTオプションを指定しますが、実際に絞り込みインデックスを利用するにはEntier独自のILIKEオプションを指定する必要があります。
<絞り込みインデックスの作成>
CREATE INDEX K_STREET_IDX
ON ZIPCODE
(
K_STREET
) INCREMENT;
<絞り込みインデックスの利用例>
SELECT PREF,CITY,STREET FROM ZIPCODE WHERE K_STREET ILIKE '%'
この機能を利用することで、実際にデータを見にいくのではなくインデックスから情報を取るため高速に該当数を取得でき、これらのAPIを利用することで、100件以下に絞り込んでからデータを表示するようなアプリケーションを作成できます。
絞り込みインデックスの構造ですが、各インデックスエントリのキー値を1バイトごとに分割して、各文字コードの重複数と、その文字コードに続く文字(候補文字)の格納位置に関する情報を保持することで、一般的なBツリーインデックスと同様に利用できます(図4)。

以上がインデックスの概要です。
続いて、実際にインデックスを作成して、利用する場合について解説します。
データベースでインデックスを利用するには、利用者が明示的にインデックスを作成する必要があります。インデックスは、以下のCREATE INDEX構文を利用して作成します。インデックスにはNULL値を含まないもの[NOT NULL]や、同一の値を含むことのできないもの[UNIQUE]などがあり、SQLのCREATE INDEX構文にて作成します。
CREATE [UNIQUE] INDEX <インデックス名> ON <テーブル名> (列名1,列名2,……) [NOT NULL];
インデックスの作成は一般的にテーブルの設計時に行います。検索を行うことが多い列に対してインデックスを設定します。例えば、郵便番号と住所が入った郵便番号テーブルの場合、郵便番号を基に住所の検索を行うことが多いと判断したら、郵便番号の列にインデックスを作成します。
Bツリーインデックスは「ルーフノード」「ブランチノード」「リーフノード」に分かれた構造になっています。インデックスの各キーはリーフノードに昇順で格納されており、実際のデータが入っている行番号などの情報が書かれています。その上のブランチノードおよびリーフノードにはデータが入っているエリア情報などが書かれています。
図5はBツリーインデックスと実際のテーブルの物理データとの構造をイメージにしたものです。
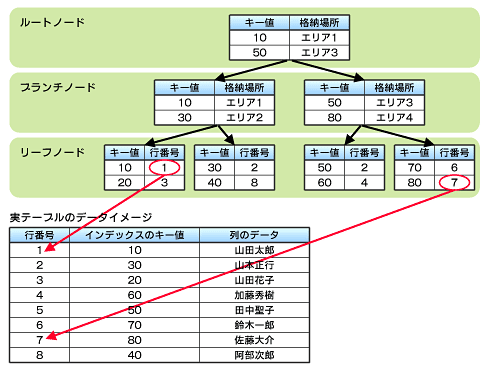
例えば、図5下部の実テーブルのデータのイメージを見てみると、実際のデータはキー値順には並んでいません。しかし、Bツリーインデックスを利用することで、キー値から欲しいデータを検索できます。
インデックスを利用しない場合、検索はすべて逐次検索(テーブルスキャン)となり、データの先頭から検索することになります。そのため、データ量が多くなればなるほど検索時間がかかります。インデックスを利用すればキー値を利用し、リーフノードで行番号などの行を特定する情報を入手できるため、高速にデータを検索できます。
一般的にインデックスは固定長の文字型の列(CHAR型)に設定します。可変長の文字型の列(VARCHAR型)に設定すると、固定長の文字型の列に比べてインデックスが大きくなり過ぎる傾向があり、こちらも更新スピードが遅くなるという問題が発生します。
ここで注意ですが、一般的にインデックスは“完全一致”か、“前方一致”でしか検索できません。つまり、テーブルに「アットマークアイティモノイスト」というデータがあった場合、「モノイスト」だけでは検索できません。もし、「部分一致」を利用するためには、N-gramインデックスなどの部分検索に対応したインデックスを利用するか、前述したインデックスを利用せずにLIKE文を利用して逐次検索(テーブルスキャン)で実現するかになります。また、インデックスを使用することで検索を速めることができますが、1つのテーブルにあまりにも多くのインデックスが存在すると、データの更新時に物理データとともにインデックスデータの更新が必要となるため、更新スピードが遅くなるという問題が発生します。そのため、検索のパターンを事前に検討しておき、それに合ったスキーマ構造にしておく必要があります。
データベースの内部構造についてはここまでとし、次回からはリレーションデータベースのスキーマ設計に必要な「正規化」についてと、「組み込みデータベースを利用するための知識」について解説していく予定です。お楽しみに!(次回に続く)
Copyright © ITmedia, Inc. All Rights Reserved.
 いまさら聞けない 組み込みデータベース入門
いまさら聞けない 組み込みデータベース入門