CAE高速化のために検討すべきGPU活用
GPUの高い並列計算能力を本来の用途であるグラフィックス以外の処理にも活用するGPGPUの有力なアプリケーションの一つがCAEだ。CAEの計算処理はCPUで行うのが一般的だが、この“常識”に変化が起こりつつある。
もっとも、どんなCAEアプリケーションでもCPUをGPUに置き換えるだけで計算速度が向上するわけではない。構造解析などに広く用いられている有限要素法は、GPUを用いても大きな効果は得られない。
GPUを用いることで計算速度の向上が期待できるCAEアプリケーションの代表格がFDTD法を用いた電磁界解析だ。グラフィックス処理と同様のシンプルな計算を数多く実行するという特性上、GPUによる並列計算がマッチするのだ。熱流体解析もGPUのメリットを比較的得やすいとされている。
CAEの手法によっては単精度演算性能ではなく倍精度演算性能が求められることもある。CAEアプリケーションにGPUを応用する際は、GPUの仕様を見極めておくことも重要なポイントだ。
ワークステーションによるCAE運用のメリット
高性能のGPUはサーバに組み込んで運用することが多いが、そのためには大容量の電力供給や冷却設備を備えた専用のマシンルームを確保しなければならないなど、導入のハードルは高い。
このため、オフィスのデスクサイドでも運用できるワークステーションにGPUボードを組み込んでCAEを利用するというニーズが大きくなっている。このようなニーズに対応するワークステーション向けGPUボードとしてNVIDIAが提供しているのがAmpere世代のNVIDIA RTX A800 40GB Active(以下、A800)だ。前世代のCAE向けGPUボードであるQuadro GV100(Volta世代)と比べて大幅な性能向上が図られている。
GPUボードのハイエンド製品としては、最新のAda Lovelace世代であるRTX 6000 Adaもあり、これら3つのGPUボードをグラフィックス処理性能に関わる単精度演算性能で比較すると、Quadro GV100の14.8TFLOPS、A800の19.5TFLOPSに対してRTX 6000 Adaは91.1TFLOPSという圧倒的な処理速度を示している。
ただし、一部のCAEアプリケーションの高速化に要求される倍精度演算性能になると状況が変わってくる。Quadro GV100の7.4TFLOPS、A800の9.7TFLOPSに対して、RTX 6000 Adaは公式には倍精度演算に対応していない。GPUによるCAEの高速化を目指す場合、このことを考慮しておく必要がある。
 2基のA800をNVLinkで接続することで、PCIe接続よりも高速な通信が可能に(提供:アスク)
2基のA800をNVLinkで接続することで、PCIe接続よりも高速な通信が可能に(提供:アスク)FDTD法を用いた電磁界解析のベンチマークテストを実施
ここからは、GPUボードを組み込んだワークステーションによるCAEの演算性能を比較したベンチマークテストの結果を紹介する。
使用したワークステーションはレノボのThinkStation P7/PX。デュアルスロットのGPUボードを2基搭載して並列処理させることも可能な、電力供給と冷却能力を十二分に備えた信頼性の高いワークステーションだ。
CAEの計算処理は、FDTD法を用いた電磁界解析で比較した。CPUによる計算速度を1としたときに、各GPUボードがどんな相対性能を発揮するのかをベンチマークテストの基準とする。
 ベンチマークテストに用いたThinkStation P7/PX(提供:アスク)
ベンチマークテストに用いたThinkStation P7/PX(提供:アスク)RTX A800はCPUの10.8倍の処理速度 RTX 6000 Ada比でも1.5倍超に
ベンチマークテストの結果、CPU計算に対してGPU計算の速度は、Quadro GV100が4.4倍、RTX 6000 Adaが7.0倍、そしてA800は10.8倍となった。単精度演算処理性能で圧倒するRTX 6000 Adaに対して、A800は1.5倍超の性能を発揮した。この要因はCAEの計算処理を律速するメモリの帯域幅の違いにある。A800のHBM2メモリの帯域幅はRTX 6000 AdaのGDDR6 SDRAMの約1.6倍に達するのだ。
ThinkStation P7/PXはデュアルスロットのGPUカードを2基搭載できるのでA800を2基搭載してベンチマークテストを実施したところ、CPUとの比較で19.4倍まで性能が向上することも確認した。
上記の結果からも分かる通り、CAEアプリケーションの高速化を求めているのであればA800の採用を検討してみてはいかがだろうか。詳細については、ぜひ販売代理店のアスクに気軽に相談してほしい。
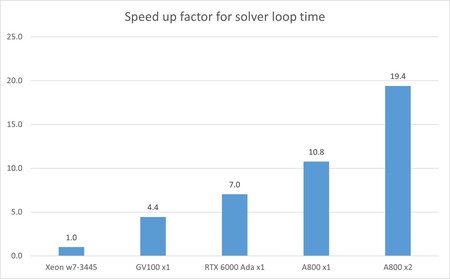 FDTD法を用いた電磁界解析のベンチマークテスト結果(提供:アスク)
FDTD法を用いた電磁界解析のベンチマークテスト結果(提供:アスク)Copyright © ITmedia, Inc. All Rights Reserved.
提供:株式会社アスク
アイティメディア営業企画/制作:MONOist 編集部/掲載内容有効期限:2024年10月31日
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。